引言
在深度学习领域,一类常见且有用的idea是向模型喂层次性的信息。例如,能提取不同感受野信息的注意力金字塔(Feature Pyramid Networks)相比传统的CNN网络图像识别效果更好,而region feature(Faster-RCNN)也相比单一的grid CNN feature能提供更多关于小样本的信息。
适用于图像领域的层次性idea同样可以用在NLP上。对于image caption模型而言,各word的权重、级别信息并未直接地送入模型中进行学习,因此模型只是被动地拟合elephant、cow、animal,而难以注意到前两者从属于后者,这可能导致视觉表示和概念词之间的不可预测的映射。而如果事先捕获了概念词之间的相互依赖关系和层次关系,那么它们可以帮助我们的模型生成更细粒度的、合理的短语和搭配,如下图所示。
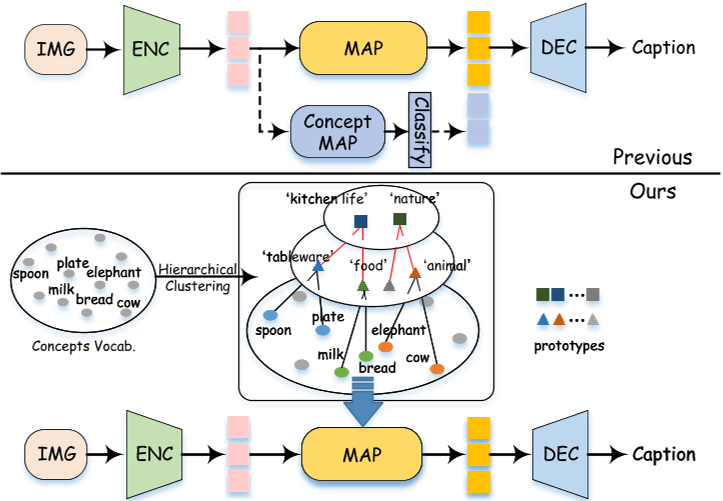
本文将介绍一篇ACM 2022的论文《Progressive Tree-Structured Prototype Network for End-to-End Image Captioning》,该论文使用聚类算法提取了caption集中所有实词的分级信息,并将各级别的word聚类簇作为嵌入向量,逐层输送到所设计的渐进式树结构原型网络(PSTN)中,最后使用transformer decoder输出caption,在 MSCOCO 数据集上实现了新的最先进的性能。论文代码发布在Github上。
该论文的主要贡献如下:
- 是第一个在图像字幕模型上建模概念的分层语义信息的尝试,这被称为树结构原型(TSP)。
- 提出了一个渐进聚合(PA)模块,使视觉网格特征以从粗到细的方式从树结构原型中捕获这些信息。
- 在MSCOCO数据集上进行了广泛的实验,并达到了一个新的最先进的结果,大大优于其他竞争对手,甚至优于许多大规模的视觉语言预训练方法。
模型结构
论文提出的渐进式树结构原型网络 PTSN(Progressive Tree-Structured prototype Network)的结构如下:
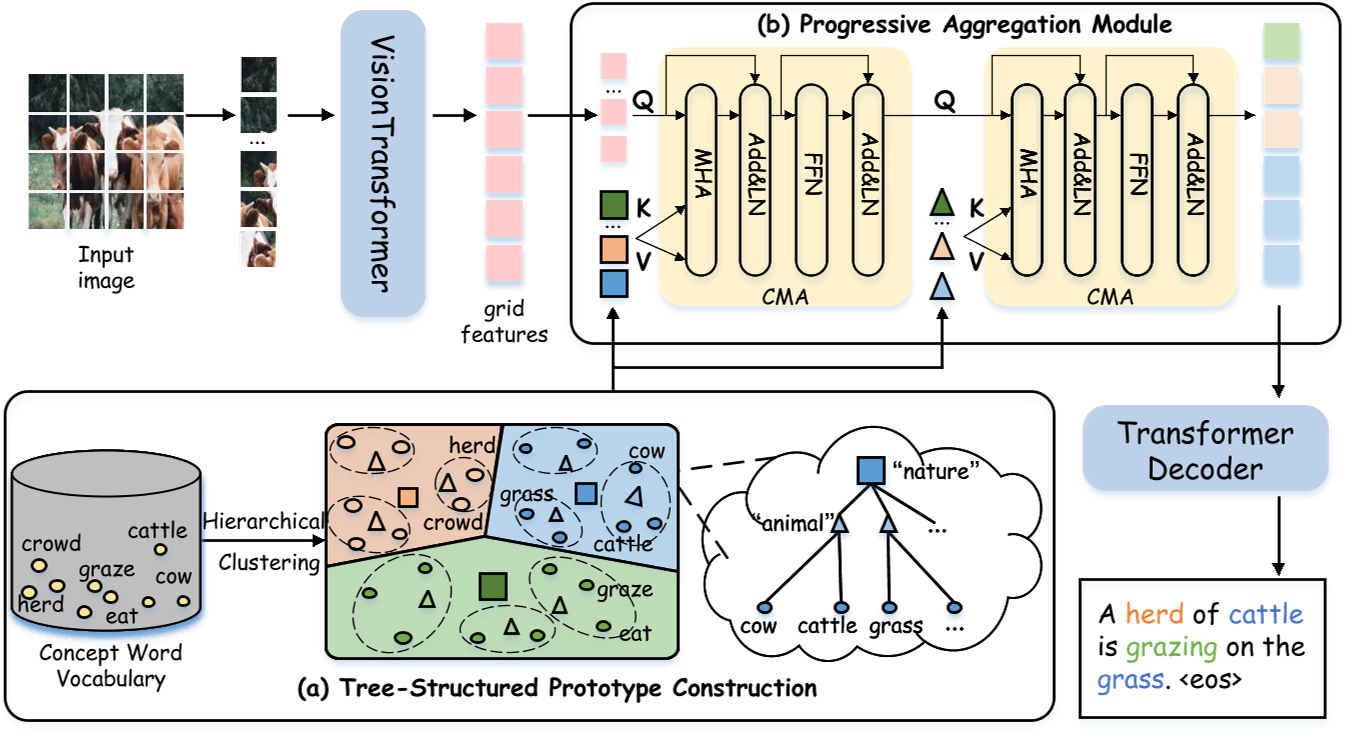
PTSN由四个主要组件组成:
- Vision Transformer,从原始图像中提取网格特征;
- 树结构原型构建模块(TSP),基于概念构建树结构语义原型;
- 渐进聚合模块,将树结构原型注入网格特征中,获得语义增强的视觉特征;
- Transformer Decoder,用于生成最终描述。
下面将分别介绍模型的关键组件。
Vision Transformer
Vision Transformer的核心在于:将一张图片分割为网格状的多个patch,并添加必要的位置编码,然后送入transformer encoder中,从而搭建了transformer到视觉领域的桥梁。
本文选用的backbone是微软研究并发表在ICCV 2021的swin transformer网络,该论文《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》荣获ICCV 2022最佳论文。作为一种通用的backbone结构,在各大CV任务上性能优于DeiT、ViT和EfficientNet等其他backbone网络。
树结构原型构建模块(TSP)
作者收集了caption词汇表中所有的动词、名词和形容词作为概念词汇,通过预训练模型(如BERT)得到各词汇的word embedding,根据这些数据,利用聚类算法(如k-means)对这些概念词汇进行递归聚类,得到一定层数、每层有一定数目原型的树结构语义原型(这里的原型翻译自prototype,指聚类子簇),相当于一个语言的树状图。越高层的词汇外延越广泛,越底层的词汇指代范围越小。
渐进聚合模块(PA)
PA的本质实际上仍然是一个transformer decoder,为了把TSP提取的语言信息融进去,作者设计了一个跨模态多头注意力(CMA)(除了输入的信息类型不同外,与MSA没有差别),第i层PA的公式表示如下:
$$\widetilde{G_i}=LN(G_i+MHA(W_QG_i,W_KZ_i,W_VZ_i)),$$
$$G_{i+1}=LN(\widetilde{G_i}+FFN(\widetilde{G_i}))$$
其中,LN、MHA、FFN分别是LayerNorm、多头注意力、前馈网络,与transformer decoder中的结构一致,$G_i$是上一层PA的输出,$G_0$是backbone提取出的image feature,$Z_i$表示树结构语义中第i层的所有原型的center(论文、代码未作过多说明,合理猜测是embedding平均值)。
原论文第一个公式有误,本文根据源代码重新校正了
训练细节
以下训练细节有必要说明:
- 训练分为两阶段:首先使用交叉熵损失训练,之后针对CIDEr使用强化学习方法SCST训练。
- 数据集使用MSCOCO,采用Karpathy split。
- 作者采用了3种聚类簇数:400、800、2000。
性能对比
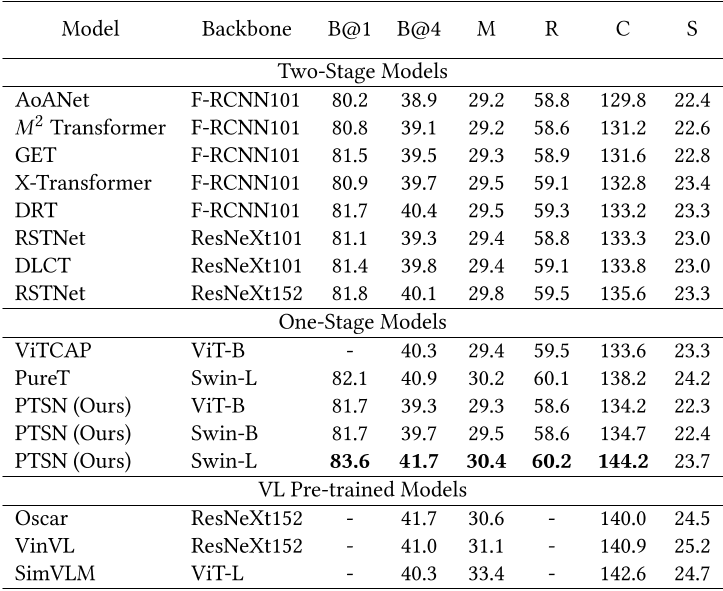
上图中,Two-Stage Models指使用backbone已经提取的离线的image feature参与训练,而One-Stage Models指对backbone和其他网络结构联合训练,VL Pre-trained Models指使用了视觉语言预训练模型。
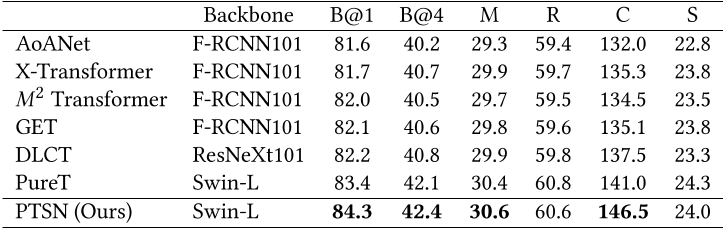
将4个模型集成得到一个更大的模型,其表现会更好,如上图所示。
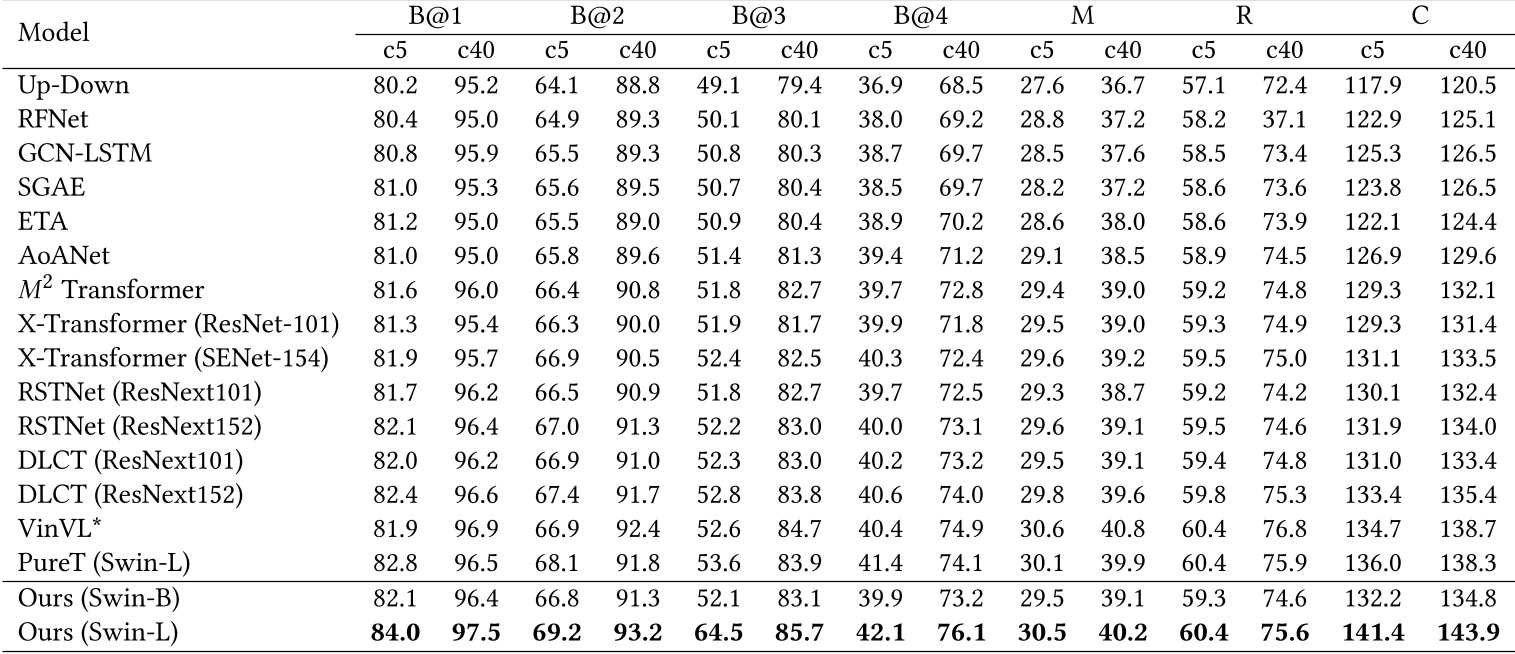
从上图可以看到,模型在MSCOCO在线测试中也取得了最佳表现。
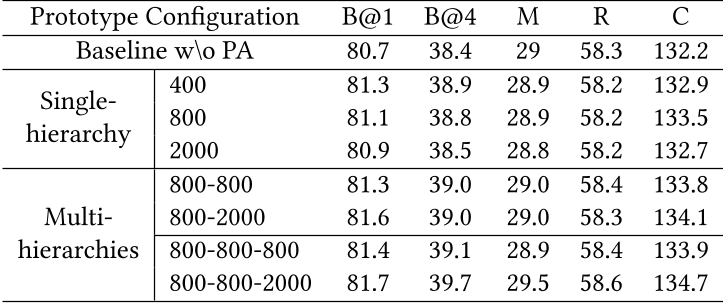
作者还对比了聚类时层数、簇数对模型性能的影响。结果表明,多层级、适中的簇类数时模型性能最好,原因是此时树结构语义原型能提供最多的语义分层信息。
结论
该论文提出了一种新的纯基于transformer的模型PTSN,用于端到端图像字幕。所提出的树结构原型模块从先前孤立的概念中获取分层语义结构,模型中的渐进聚合模块用来帮助视觉特征从树结构原型中学习更细粒度的视觉语义信息。大量的结果证明了该方法在离线和在线测试拆分上都取得了新的最先进的结果,甚至超过了一些大规模的预训练视觉和语言模型。
思考
- 概念词汇中忽略了虚词,显然多语义的虚词与其他单词的关系难以用树状图表示,是否有合适的数学结构能够容纳虚词呢?
- 模型只笼统地利用了所有词汇的所属层级信息,但忽略了单个词与词间的关联信息,能否设计模型以利用树结构语义原型的更多信息呢?
- 单词往往是多义的,或许有必要在聚类时考虑到这一点。
- 聚类数据的来源来自于语言预训练模型,在模型训练过程中不可改变,这可能掩盖了树结构语义原型在训练数据集中的的不适用性,能否在模型训练时视需要动态地改变树结构语义原型呢?
- 越多的层级意味着越多的decoder layer,这会带来昂贵的训练成本。实际上,利用层级信息并不需要堆叠decoder,对于有n层的树结构语义,我们可以将训练分为n个阶段,第i阶段的交叉熵损失只关注模型是否在第i层语义上预测正确,每层训练loss降到一定阈值后进入下一阶段,直至所有层训练完毕。这个方法让模型逐步适应词汇数目的增多,且只需一层decoder即可训练,效果会如何呢?