0. 前言
Cross-Domain Image Captioning with Discriminative Finetuning,2023年发表在CVPR的关于Image Caption的三篇文章之一,其论文PDF也可在arXiv上找到。
第一作者是Roberto Dessì,他目前工作于Meta AI Research,其个人主页上也可以看到他的其他文章,而本文所介绍的论文也是他最新的一篇顶刊论文。
1. 概述
一般来说,我们训练一个Image Caption模型,通常都是以人类生成的语言为参考目标,但是这种训练策略通常会有语言模糊的问题。
这篇论文的作者基于强化学习、对比学习等方法,提出了一种能提高模型跨域泛化能力(zore-shot)的新的微调方法DiscriTune,能够增强模型对图片语言描述的判别性(discriminative)。作者强调了这样一种思想:“There are a multitude of context-dependent purposes a description might be produced for, but a fundamental one is to correctly characterize an object so that a hearer could discriminate it from other contextual elements.” (生成一个描述可能较多基于与上下文相关的目的,但最基本的目的是正确地描述一个对象,以便听者能够将其与其他上下文元素区分开来)。直观地理解就是,经过这种微调手段后,你看到模型输出的caption之后,能容易地从一大堆图片中找到原图片。
这篇论文主要用到了一系列较为前沿新颖的概念。因此,在开始正文前,让我们先来回顾一些基础模型和方法。
已熟悉这些概念的有经验的读者可直接从第3章开始阅读。
2. 基础概念
2.1 强化学习
关于如何学习强化学习,我推荐两个网站:动手学强化学习和强化学习蘑菇书EasyRL. 前者注重代码实践,后者注重理论的讲解。学习的过程中可以把两者结合起来学习。下面我简单介绍一下强化学习的概念和它在Image Caption领域的实际应用。
2.1.1 概念
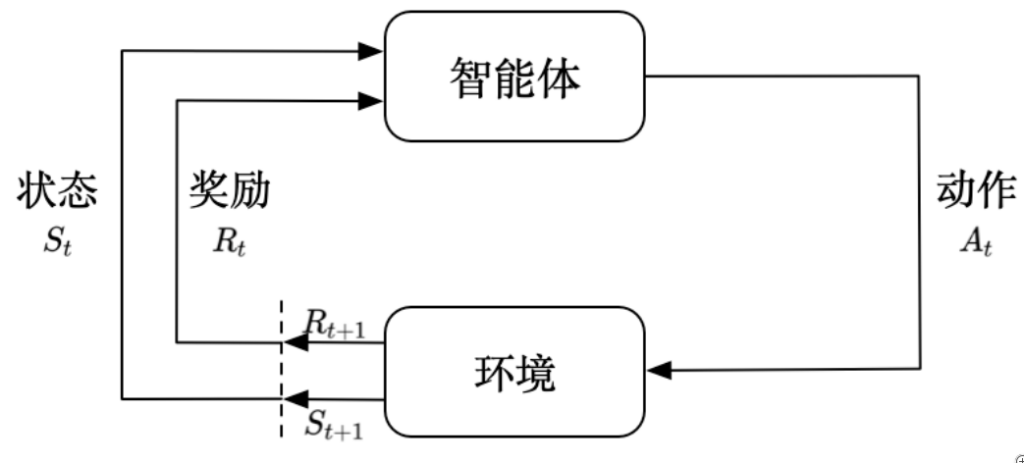
强化学习(reinforcement learning,RL)讨论的问题是智能体(agent)怎么在复杂、不确定的环境(environment)中最大化它能获得的奖励,如上图所示。
用一个案例来说明:假设你在学习怎么走路,你先根据当前街道环境(环境状态$S_0$)依据你的策略(policy)思考并走出最初的步伐(动作$A_0$),这时你周边的环境肯定会发生变化,比如你前进了一步,那么街道环境就会改变一步,环境更新为新的状态($S_1$)。另外,如果你的动作(动作$A_t$)不正确,那么你也可能摔倒,这时我们说环境对你产生了一个较低的或负的奖励($R_1$)。最后,你根据新的环境($S_1$)和奖励($R_1$)思考并走出新的一步($A_1$),如此往复直到结束。
在以后的应用中,我们需要额外关注这几个概念:
- 动作(action):智能体对环境施加的作用。不同的环境允许不同的动作。
- 策略(policy):智能体根据状态和奖励做出新的动作所依据的方法就是策略,可分为随机性策略和确定性策略,后者一般可写作$\mathop{\arg\min}\limits_{a}\pi(a|s)$。
一般来说,在Image Caption里,以transformer decoder为例,一个layer就可以看成是一个智能体。这个layer接收之前layer的输出为输入,并在当前时间步输出一个新的单词,因此可以把这个单词作为智能体的动作,而上一时间步的输入可以看作是环境的新状态,layer内部参数可以看成是决定策略的参数。奖励函数有多种设置方法,一种简单的奖励方法是在时间步结束时利用BLEU、SPICE等评价指标作为奖励信号。
如果想对decoder输出的loss进行反向传播可能会遇到离散、不可求梯度或计算成本高等困难,这时强化学习就派上用场了。
2.1.2 Image Caption强化学习应用
本节主要介绍强化学习在Image Caption中的应用历程。
早期的工作基本上是在探究如何改进奖励函数。第一篇开创性工作归功于Ranzato等人[3],将BLEU和ROUGE作为奖励函数进行强化学习,以克服teacher forcing在测试时造成的不稳定的后果。liu等人[4]提出将SPICE与CIDEr分数的线性组合作为奖励,利用策略梯度算法进行训练。Ren等人[5]引入了actor-critic强化算法,并修改了奖励函数,将图像embedding与生成的caption的相似度作为奖励,以此提高生成描述的准确度等指标。
后续较多的研究基于Rennie等人的成果[6],他们使用基线改进策略梯度算法,减小算法对梯度的估计方差。但他们没有使用过往数据来“估计”基线,而是把网络测试时贪婪解码的分数作为基线值(与actor-critic的价值估计网络相区别),降低了训练时间。
总的来说,Image Caption领域的强化学习算法基本上是基于策略梯度算法或actor-critic算法的,且一般把循环神经网络结构,如decoder作为agent. 大部分论文聚焦于研究如何设计高效的奖励函数,这不仅包括数学上的改进,还包括引入一些新的网络结构。
2.2 CLIP
论文链接:https://arxiv.org/abs/2103.00020
CLIP是一种基于对比文本-图像对的预训练方法或者模型,尝试使用文本作为监督信号来训练可迁移的视觉模型,提高了zero-shot分类能力。
详细的论文讲解可以参考神器CLIP:连接文本和图像,打造可迁移的视觉模型 – 知乎。
2.3 ClipCap
论文链接:https://arxiv.org/abs/2111.09734
ClipCap提出了一种基于Mapping Network的Encoder-Decoder模型,其中Mapping Network扮演了图像空间与文本空间之间的桥梁。模型主要分为三部分:
- 图像编码器:采用CLIP模型,负责对输入的图像进行编码,得到一个图片向量clip_embed。
- Mapping Network:扮演图像空间与文本空间之间的桥梁,负责将图片向量clip_embed映射到文本空间中,得到一个文本提示向量序列prefix_embeds。
- 文本解码器:采用GPT2模型,根据提示向量序列prefix_embeds,生成caption。
详细的论文讲解参考ClipCap:让计算机学会看图说话 – 知乎。
3. 实验介绍
3.1 原理结构
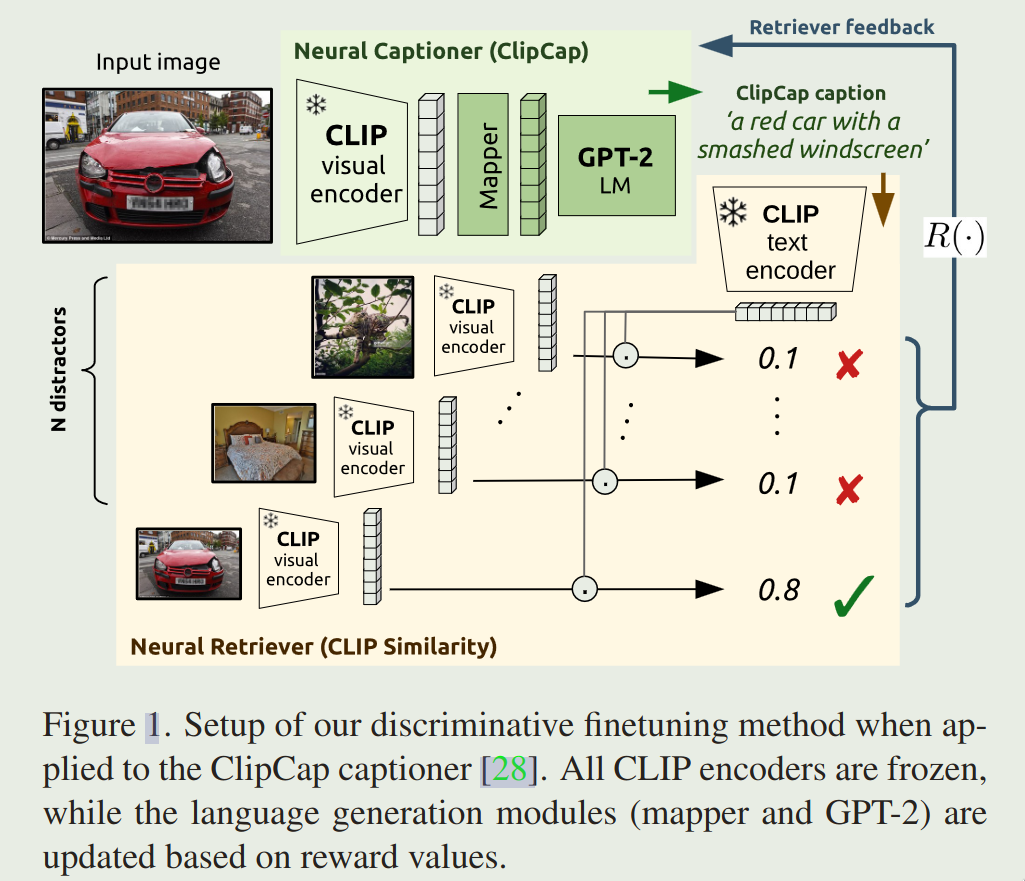
微调方法如上图所示,其模型结构可分为2个部分:
- Neural Captioner:即根据图片输出说明文字的网络,这里主要用的是ClipCap网络来搭建。
- Neural Retriever:这是整个微调方法的核心,即评价Neural Captioner生成的caption在多大程度上能从一堆干扰项中分辨出原图片。
执行上面两个步骤之后,将retriever的评价分数设计为reward函数,使用强化学习中的策略梯度算法对ClipCap中的网络参数优化,进而实现微调目标。
一些网络使用预训练权重,并在训练期间不优化参数(冻结),这些网络在图中用雪花图案❄️标明。
captioner的部分和刚才讲的ClipCap一模一样,因此不再赘述。使用ClipCap的原因,作者说是ClipCap使用了较少的参数,以及拥有较快的训练速度。这里作者使用了ViT-B/32-based CLIP作为图像特征提取网络,并借用了两个公开的checkpoints,ClipCap-ConCap和ClipCap-COCO.
对于Retriever网络,这里基本的网络框架仍然是CLIP中的对比学习,使用了以ViT-B/32为backbone的CLIP,步骤是让ClipCap中处理视觉图像的visual encoder输出和caption相互对比,输出二者的匹配度,但这里的匹配值不像原始的CLIP那样是余弦相似性矩阵,而是用了作者所设计的softmax log probability函数:
$$R(c,i,D)=log\frac{e^{match(c,i)}}{\sum_{i’\in D\cup {i}}e^{match(c,i’)}}$$
其中,$c$和$i$分别代表caption和image,D是随机采样的99个干扰图片,$match$是CLIP论文中的余弦值计算函数。使用这种函数,相比于原来的match,能够考虑到captioner模型输出描述的判别能力。因此,作者将其作为奖励函数,captioner训练模型作为agent,$P_\theta(c|i)$则作为policy,训练的目的是最小化$\mathbb{E}_{c\sim P( \cdot |i)}[-R(c,i,D)]$.
作者使用策略梯度算法,并将过往的rewards的平均值作为算法中的基线。
3.2 数据集
判别微调的数据集选择MS COCO(使用Karpathy分割训练、测试集)和Conceptual Captions(仅作为测试集)。过滤损毁的数据后,训练集共2.8M个样本,测试集共13K个样本。
为了测试跨域泛化能力(0-shot cross-domain generalization),使用了flickr(karpathy split)、nocaps(使用near-domain和out-domain部分的图像)和concadia(使用其测试分割集)数据集。Concadia 是最近引入的数据集,用于在与描述相比生成描述时测试文本生成性能差异。前者旨在伴随图像以提供额外的上下文,如书籍或报纸,而后者用于替代图像,一个例子是视障人士的描述(discription)。论文使用包含 9.6K个 图像的 Concadia 测试拆分,每个图像都带有caption和discription。
需要强调的是,微调过程中不会使用任何人类参考(human reference),groud-truth captions仅用于计算反映实验效果的NLG指标。
最后,针对学习率、奖励函数和策略梯度算法基线的选取,使用Flickr作为验证集来调参优化。(调参过程及性能对比见论文附录B)
3.3 训练方法
使用DiscriTune方法,冻结部分网络的权重(3.1节已给出),CLIP权重使用ClipCap- coco和ClipCap- concap这两个checkpoint,对COCO和CONCEPTUAL Captions两个数据集微调,将得到的微调模型称为DiscriTune-COCO和DiscriTune-ConCap。此外,对使用COCO训练的BLIP checkpoint重复主要实验,并使用DiscriTune方法进一步微调。
使用Adam优化器,学习率设为恒定的$10^{-7}$。batch size为100,以便每个目标图像与99个随即采样的干扰项混合进行判别微调。COCO和Conceptual Captions实际训练分别花了20个和2个epoch。对于BLIP,仅进行一个对应于1.2k次更新的epoch,因为初步实验表明足以收敛。
对于解码过程,训练时使用greedy decoding,而测试时使用beam search。
4. 实验效果
4.1 基于文本的图像检索
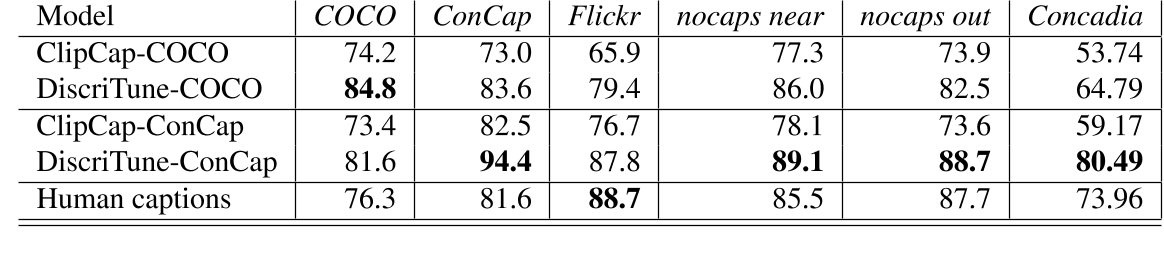
给定caption,检验模型从100个候选图像中检索目标图像的准确度。上表表明:
- 使用DiscriTune之后相比原来的ClipCap模型精度更高。
- cross-domain方面,DiscriTune-COCO在ConCap上的表现(83.6)稍微优于 ClipCap-ConCap(82.5),而 DiscriTune-ConCap 在 COCO 上(81.6)大大优于ClipCap-COCO(74.2)。此外,两个版本的 DiscriTune 在所有其他数据集上都大大优于ClipCap。
4.2 基于Ground-Truth的caption质量评价
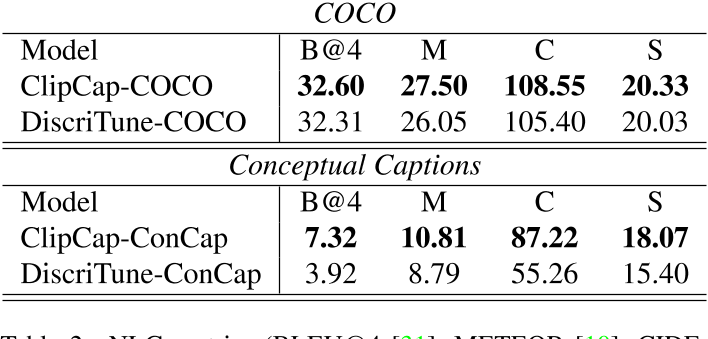
上表给出了模型输出caption的NLG指标度量。可以看到,在用于监督预训练的数据集上测试时,判别微调会导致描述准确度略有下降。然而,这种性能下降(在 COCO 的情况下非常小)通过更大的泛化性能来平衡,如下表所示:
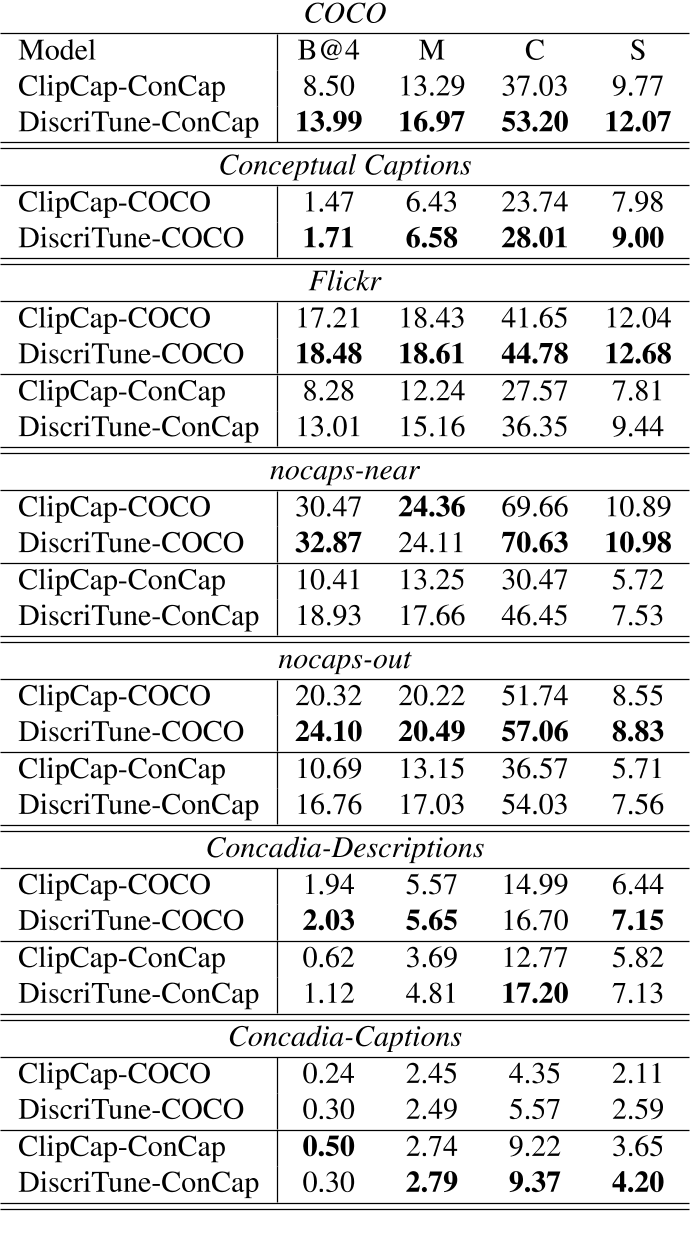
可以看到,DiscriTune方法在跨域泛化性上有很大的优势。有趣的是,对于 Concadia 数据集,我们使用描述拆分而不是caption拆分,相较于ClipCap能 获得(轻微)更高的增益,尤其是对于 DiscriTune-ConCap。描述拆分中的人类参考描述是通过描述其内容来替代图像来生成的。这证实了 DiscriTune 更适合表征图像内容关键方面的“交流”目的的描述(这体现出了判别微调方法的优势)。
总体而言,结果表明,一方面,判别微调会导致描述偏离模型学习模仿的人类描述。然而,与此同时,这可能允许模型远离特定描述风格的能力,从而导致更好地泛化到更广泛的图像和领域的描述。正如下面第 4.4 节中的实验所示,即使在同一域中描述图像时,这种漂移也可能是有益的。
4.3 对BLIP应用判别微调
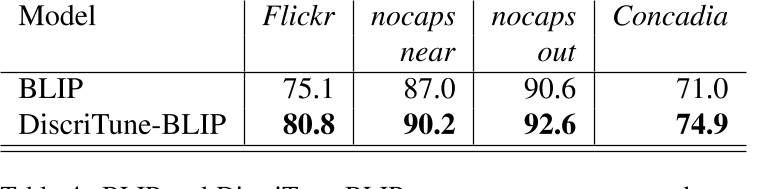
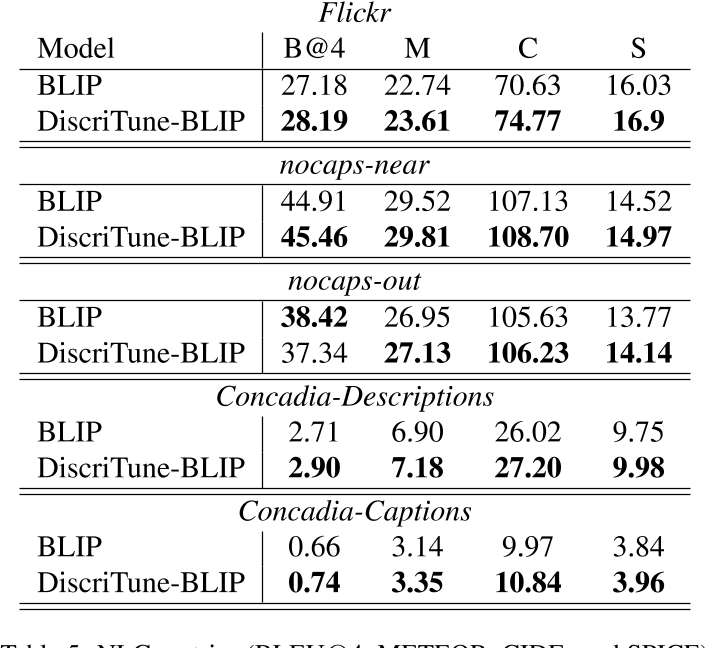
为了验证 DiscriTune 微调的鲁棒性,接下来将其应用于 BLIP。作者在 COCO caption上微调 BLIP,这是它预训练的数据集之一。上面两个表格表明,DiscriTune-BLIP 在检索性能和描述质量方面都优于其非微调的BLIP。结果表明,即使应用于BLIP这种新一代通用视觉和语言模型,DiscriTune也很有帮助。DiscriTune-BLIP 在测试的所有域外数据集上都优于BLIP。同样,我们注意到与captions拆分相比,Concadia descriptions拆分的性能提升更大,这证实了使用 ClipCap 获得的结果以及我们的微调方法生成更接近人类参考的标题的好处,即这些描述具有替换图像的交流意图。
鉴于 BLIP 不是基于 CLIP 编码器,该实验还反驳了一个假设,即消除性能提升仅仅是因为使用 CLIP 作为描述器和检索器的视觉编码器,证实了我们方法的更广泛适用性。
4.4 基于人类文字的图像检索
之前的结果表明,DiscriTune-ConCap 产生的输出与人类文字的相似度低于 ClipCap-ConCap 的输出,但在基于文本的图像检索准确性方面大大优于后者。
回想一下,Conceptual Captions中的ground-truth caption来自与从Web收集的图像相关联的alttext。当脱离上下文时,这样的标题通常没提供太多信息,因此学习尽可能地再现它们的风格,如 ClipCap-ConCap一样,可能不是一个很好的想法。
例如,考虑下图 (c),H、C和D分别代表人类参考、ClipCap和DiscriTune。ClipCap-ConCap 完美地再现了真实描述(“为 # 选择的数字艺术”),但这并不像 DiscriTune-ConCap(“池塘中的男孩有很多星”)。因此,我们推测,尽管 DiscriTune对人类基本事实的忠实度较低,但它相比ClipCap更具有丰富的信息,并且可能比这个数据集里的人类参考有更丰富的信息。(更详细的描述质量对比见附录E)
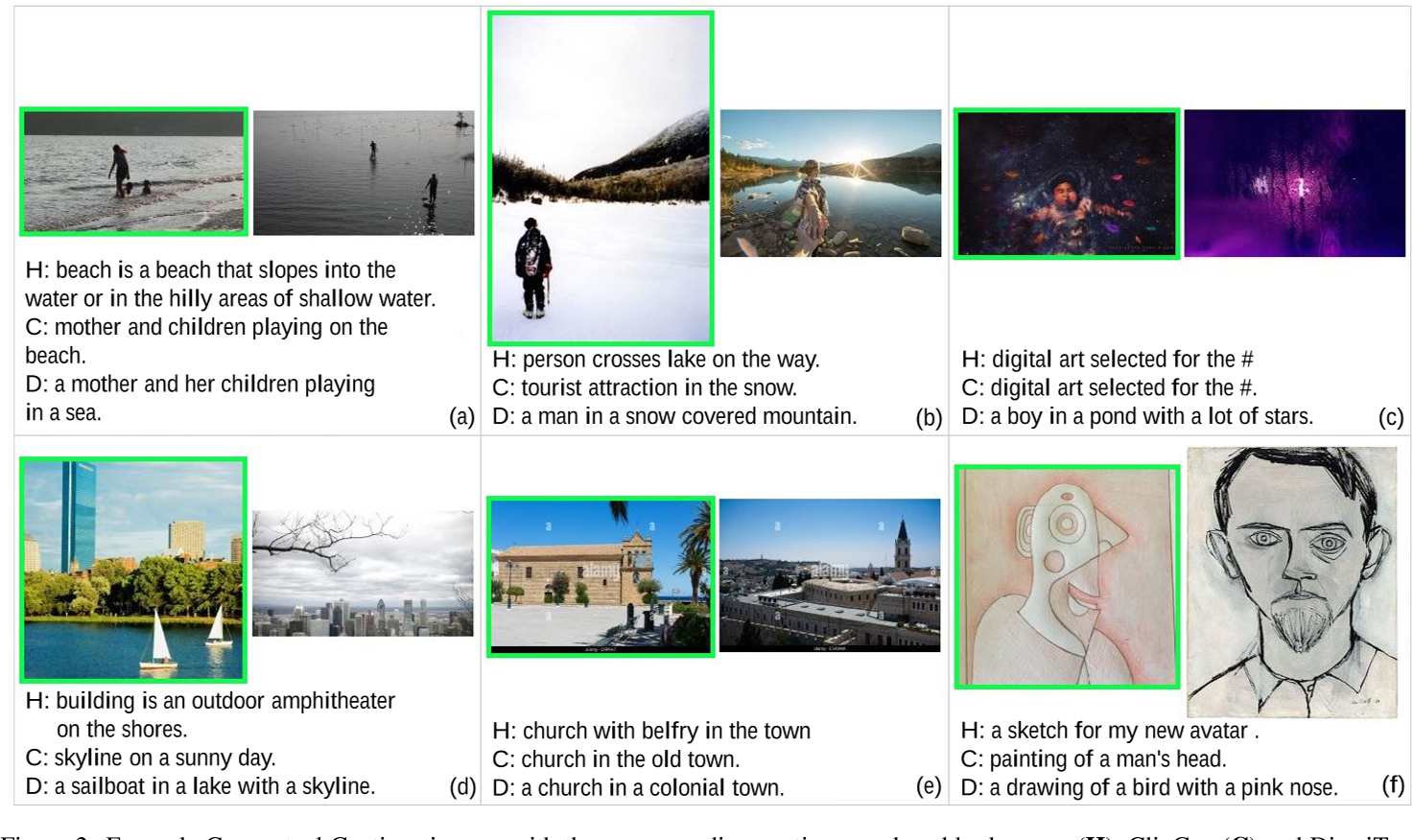
为了验证这一假设,作者设计了一个人类注释者参与的实验,感兴趣的读者可以在论文附录A中看到实验设计的细节信息。结果表明,DiscriTune-ConCap 描述不仅大大优于ClipCap ,而且大大优于人类描述,准确率提高了 5%.
5. 结论
- 论文基于强化算法,提出了一种简单的判别微调方法,使模型生成的描述更具鉴别力。
- 当在训练captioner的同一数据集上进行测试时,有区别地微调的描述在与人类真实描述的相似性方面并没有比原始描述有所改善。然而,对于两个DiscriTune模型和各种域外数据集,它们始终优于原始captioner。在奖励函数中引入判别性可能是一个足够强的优化信号,能消除预训练数据集描述风格上的一些过拟合。
- 对于带噪声注释的概念描述数据集,有区别的微调描述比实际描述更有帮助,不仅对神经检索器,而且对肩负挑战性图像识别任务的人类来说也是如此。这表明,论文的系统可以按原样用于生成Web图像标题,这些标题对用户来说平均比alt文本描述(Conceptual Captions注释)更具信息性。
- 描述质量上,判别微调也能够提供更精确、更清晰的语言。
- 使用基于人类反馈的强化学习(RLHF)最近取得了进展(如GPT3),但人工标注的成本较高,而本论文提供了一种更便宜的替代方案,利用“神经”反馈来指导现有模型的微调。
参考链接
[1] 神器CLIP:连接文本和图像,打造可迁移的视觉模型 – 知乎
[2] [2107.06912] From Show to Tell: A Survey on Deep Learning-based Image Captioning
[3] Sequence Level Training with Recurrent Neural Networks
[4] Improved Image Captioning via Policy Gradient optimization of SPIDEr
[5] Deep Reinforcement Learning-based Image Captioning with Embedding Reward
[6] Self-critical Sequence Training for Image Captioning
[7] ClipCap:让计算机学会看图说话 – 知乎