前言
部署项目是一个很重要的环节,本文特指复现论文中的实验环境、训练结果。对于初学者而言,部署并复现一篇论文的代码是一件有挑战性的事,但它对于我们复现实验结果有着重要的意义。这里我将以我复现的论文为例,给大家分享一下我的搭建过程。
选择论文
我选择的论文是《Cross-Domain Image Captioning with Discriminative Finetuning》。这篇论文是在今年4月的时候发表的,是一个比较新的工作。我目前已搭建好了该代码项目的环境,目前还差测试数据集的下载、预处理。在这里,我将以这篇论文为例,给大家分享一下我的搭建过程。
代码获取
获取代码我介绍两种方法(#tip1):
- 在论文中作者提供了项目地址
优点:直接获取项目地址,省去了搜索的时间
缺点:有些论文的代码是不开源的,我们无法获取 - 在[paperswithcode](https://paperswithcode.com/)中搜索论文,获取项目地址
优点:可以获取到官方和非官方的代码,选择权更大
缺点:有些非官方代码有可能是错误的,并且可能维护时间太老,使用的库较落后,我们需要根据项目维护时间和stars数量自己去判断
很幸运的是,本篇论文的代码是开源的,我们可以在论文摘要中直接获取到项目地址。项目地址为:facebookresearch / EGG
真的这么顺利吗?
……你打开了项目链接,github提示该文件并不存在。
很不幸,你没有发现作者所声称的项目代码。你打开这个代码所在的项目主页,逛了README和项目目录一圈,甚至搜索了关键词,还是没有发现论文代码在哪里。
你遇到的问题,很可能他人也遇到了(#tip2):
- 点开issues,搜索关键词,看看有没有人遇到同样的问题
- 别忘了点击”closed”,看看有没有人已经解决了这个问题
我们可以看到,最近的两个issue都是关于《cross-domain》论文代码不在的问题。点开最新的一个issue,可以看到作者已经回复了,原来论文给的是facebook官方的项目链接,他们将代码放在了自己的仓库中,还没来得及合并。真正的项目地址为:robertodessi / EGG
注意!甚至在作者自己的仓库main分支里也找不到我们所需要的代码。仔细阅读刚才的issue,可以发现我们需要的项目在rll_refactor中,需留意branch并不是main。我们可以切换到rll_refactor分支,再次查看项目目录,可以看到我们需要的代码在emergent_captioner目录下。
这里我查看了所有分支,发现只有rll_refactor_camel作者还在活跃,且这个分支是基于rll_refactor的,故之后部署环境时我switch到的是rll_refactor_camel
项目环境
搭建项目环境的原则:
- 看官方README,看看有没有安装、部署指南。
- 注意有些项目有多个README,一般主页的README会介绍项目的整体情况,而子目录的README会介绍子目录的情况。
我们项目的安装指南如下:
Generally, we assume that you use PyTorch 1.1.0 or newer and Python 3.6 or newer.
(optional) It is a good idea to develop in a new conda environment, e.g. like this:
conda create --name egg36 python=3.6 conda activate egg36EGG can be installed as a package to be used as a library
pip install git+ssh://git@github.com/facebookresearch/EGG.gitor via https
pip install git+https://github.com/facebookresearch/EGG.gitAlternatively, EGG can be cloned and installed in editable mode, so that the copy can be changed:
git clone git@github.com:facebookresearch/EGG.git && cd EGG pip install --editable .Then, we can run a game, e.g. the MNIST auto-encoding game:
python -m egg.zoo.mnist_autoenc.train --vocab=10 --n_epochs=50
后面还有个测试脚本的指南:
Run pytest:
python -m pytestAll tests should pass.
这里需要注意:
- 项目需要使用PyTorch 1.1.0或更新版本,Python 3.6或更新版本,conda的时候记得指定python版本。我首先尝试了pytorch2.0和python3.11,但是在测试时出现了问题(报错“numpy没有np.int_属性,已在numpy 2.20被弃用,可换用np.int64”)。
什么意思呢?就是说numpy版本高了,有些功能不支持了。这里我们可以选择更换numpy版本:
conda install numpy==1.20
意外又来了,conda报错说无法解决环境依赖,python版本必须在3.6~3.10。这里我们可以选择更换python版本(其实我是先删除当前环境,又重新建了个):
conda install python==3.7
最终我选择了python3.7。
- 我们不仅是想安装egg库,也想修改egg库,所以我们选择了克隆项目并安装。这里需要注意,我们需要在项目目录下安装,否则会报错。之后执行
pip install .
我没加–editable是因为好像这样安装后python检测不到已安装这个库了
- 在运行测试脚本时提示缺少module,这是最常见也可能是最简单的问题。我们可以使用pip安装缺少的module,或者使用conda安装。依个人喜好,我偏向先用conda安装试试,不行再用pip. conda安装建议上[anaconda官网](anaconda.org)搜索包名称,在那里有安装说明。例如,我想安装缺失的包editdistance,查到安装命令为:
conda install -c conda-forge editdistance
最终,测试脚本全部运行成功。
运行前准备
运行项目前我们可能还需要准备一些东西,例如数据集、预训练权重下载等。这些信息一般在项目的README中有说明。
意外又来了!似乎由于论文太新,作者连README都没写。这时我们就需要自己去找运行脚本了。finetuning/train.py,这个脚本一看就是用来训练模型的,代码里面有很多的parser.add_argument函数,这说明要运行该脚本需要添加许多参数。获得参数help,让我们看看需要哪些参数:
python train.py -h
输出如下:
usage: train.py [-h] [--debug] [--dataset_dir DATASET_DIR]
[--train_dataset {coco,conceptual}]
[--eval_datasets EVAL_DATASETS [EVAL_DATASETS ...]]
[--sender_image_size SENDER_IMAGE_SIZE]
[--recv_image_size RECV_IMAGE_SIZE]
[--num_workers NUM_WORKERS]
[--captioner_model {clipcap,blip,camel}]
[--blip_model {base_coco,large_coco}]
[--freeze_blip_visual_encoder]
[--clipcap_model_path CLIPCAP_MODEL_PATH]
[--sender_clip_model {ViT-B/16,ViT-B/32,RN50x16}]
[--camel_model_path CAMEL_MODEL_PATH]
[--network {online,target}] [--disable_mesh] [--N_dec N_DEC]
[--N_enc N_ENC] [--d_model D_MODEL] [--d_ff D_FF] [--m M]
[--head HEAD] [--with_pe]
[--num_hard_negatives NUM_HARD_NEGATIVES]
[--beam_size BEAM_SIZE] [--do_sample]
[--loss_type {accuracy,similarity,discriminative}]
[--recv_clip_model {ViT-B/16,ViT-B/32}] [--baseline {no,mean}]
[--kl_div_coeff KL_DIV_COEFF] [--random_seed RANDOM_SEED]
[--checkpoint_dir CHECKPOINT_DIR] [--preemptable]
[--checkpoint_freq CHECKPOINT_FREQ]
[--validation_freq VALIDATION_FREQ] [--n_epochs N_EPOCHS]
[--load_from_checkpoint LOAD_FROM_CHECKPOINT] [--no_cuda]
[--batch_size BATCH_SIZE] [--optimizer OPTIMIZER] [--lr LR]
[--update_freq UPDATE_FREQ] [--vocab_size VOCAB_SIZE]
[--max_len MAX_LEN] [--tensorboard]
[--tensorboard_dir TENSORBOARD_DIR]
[--distributed_port DISTRIBUTED_PORT] [--fp16]
optional arguments:
-h, --help show this help message and exit
--debug Run the game with pdb enabled
--random_seed RANDOM_SEED
Set random seed
--checkpoint_dir CHECKPOINT_DIR
Where the checkpoints are stored
--preemptable If the flag is set, Trainer would always try to
initialise itself from a checkpoint
--checkpoint_freq CHECKPOINT_FREQ
How often the checkpoints are saved
--validation_freq VALIDATION_FREQ
The validation would be run every `validation_freq`
epochs
--n_epochs N_EPOCHS Number of epochs to train (default: 10)
--load_from_checkpoint LOAD_FROM_CHECKPOINT
If the parameter is set, model, trainer, and optimizer
states are loaded from the checkpoint (default: None)
--no_cuda disable cuda
--batch_size BATCH_SIZE
Input batch size for training (default: 32)
--optimizer OPTIMIZER
Optimizer to use [adam, sgd, adagrad] (default: adam)
--lr LR Learning rate (default: 1e-2)
--update_freq UPDATE_FREQ
Learnable weights are updated every update_freq
batches (default: 1)
--vocab_size VOCAB_SIZE
Number of symbols (terms) in the vocabulary (default:
10)
--max_len MAX_LEN Max length of the sequence (default: 1)
--tensorboard enable tensorboard
--tensorboard_dir TENSORBOARD_DIR
Path for tensorboard log
--distributed_port DISTRIBUTED_PORT
Port to use in distributed learning
--fp16 Use mixed-precision for training/evaluating models
data options:
--dataset_dir DATASET_DIR
--train_dataset {coco,conceptual}
--eval_datasets EVAL_DATASETS [EVAL_DATASETS ...]
--sender_image_size SENDER_IMAGE_SIZE
Sender Image size
--recv_image_size RECV_IMAGE_SIZE
Recv image size
--num_workers NUM_WORKERS
captioner options:
--captioner_model {clipcap,blip,camel}
Type of captioner model (default: clipcap)
--blip_model {base_coco,large_coco}
--freeze_blip_visual_encoder
--clipcap_model_path CLIPCAP_MODEL_PATH
--sender_clip_model {ViT-B/16,ViT-B/32,RN50x16}
--camel_model_path CAMEL_MODEL_PATH
--network {online,target}
--disable_mesh
--N_dec N_DEC
--N_enc N_ENC
--d_model D_MODEL
--d_ff D_FF
--m M
--head HEAD
--with_pe
--num_hard_negatives NUM_HARD_NEGATIVES
--beam_size BEAM_SIZE
Number of beams when using beam serach decoding
--do_sample
game options:
--loss_type {accuracy,similarity,discriminative}
--recv_clip_model {ViT-B/16,ViT-B/32}
--baseline {no,mean}
--kl_div_coeff KL_DIV_COEFF
必要的参数其实就那几个,有些参数还有默认值,总之慢慢试错,总会run起来。不过显而易见的是,我们需要指定训练集和验证集路径。
每次运行都要添加参数太麻烦了,我们可以把参数写到一个文件custome_args.txt里,然后直接运行(tip3):
python train.py $(cat custom_args.txt)
数据集
在运行项目前,我们需要准备一些数据集。项目中有一些数据集是自带的,但是有些数据集需要我们自己下载。这里我们需要注意,有些数据集需要我们自己下载,但是项目中没有给出下载链接,这时我们需要自己去找。
COCO很好下载,下载完后放在一个合适的位置,记得之后指定数据集参数。
预训练权重
尝试运行下train.py就会发现,又报错了!
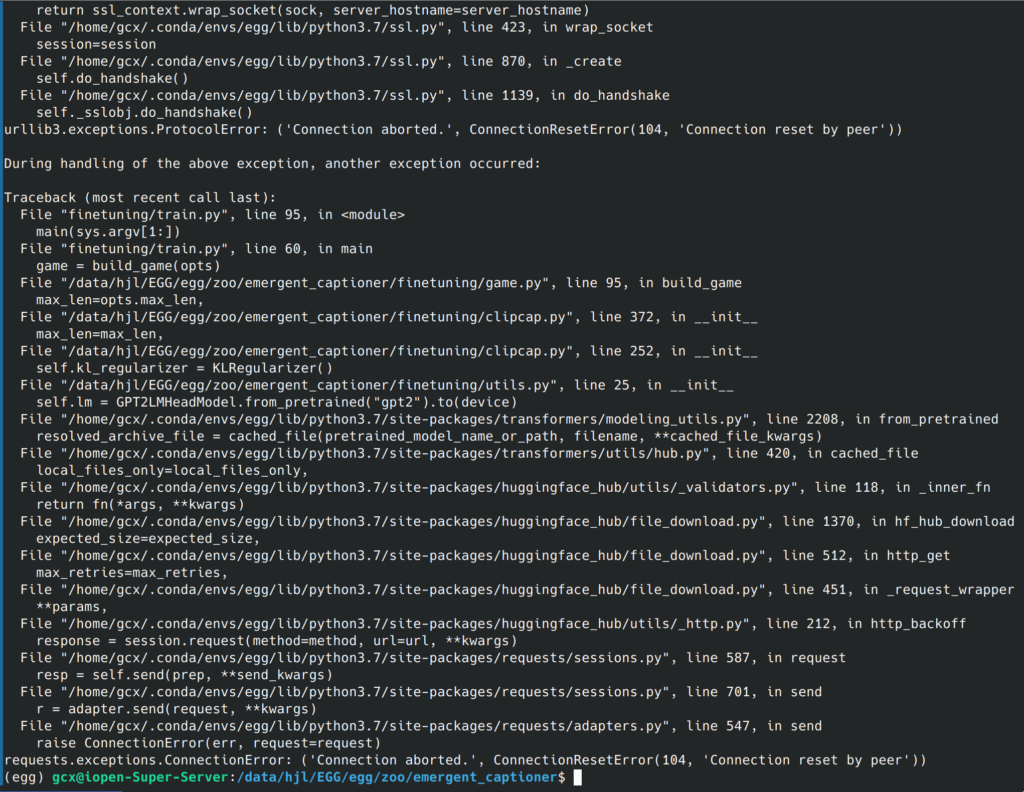
仔细一看,还报了3个error,不要慌,我们一个一个来看(#tip4):
1. 有很多traceback跟踪到python3.7/site_packages里的文件中去了,经验来说,库文件出错的概率不大,因此我们忽略这些traceback,只看在我们项目文件夹下的跟踪,最终锁定到这一行代码:
self.lm = GPT2LMHeadModel.from_pretrained().to(device)
再看最后一行,发现是requests库的ConnectionError,也就是网络问题。大致梳理一下就知道,程序没有找到预训练权重,想去huggingface下载,但是网络不通,所以报错了。这时我们需要去找一下预训练权重,放在合适的位置,然后指定权重路径参数。
欠缺的GPT2权重可以在这里下载:https://huggingface.co/gpt2/ ,网页下载速度很感人。查询官方文档可以发现还有另外的下载方式——git-lfs. 这是一个支持克隆大文件的git拓展,安装后使用以下命令下载GPT2模型文件:
git clone https://huggingface.co/gpt2 cd gpt2 git pull
我们还需要下载clipcap模型权重,这个模型是作者自己训练的,因此没有在huggingface上发布。作者在github上给出了谷歌云盘下载链接。
由于太费流量,我在huggingface上找到了别人上传的模型权重文件,套用上面的git-lfs方法下载即可。
如果你用的是个人电脑,并且不开vpn,,那么无论哪种方法下载速度其实还是很慢。我用的是腾讯云服务器,下载速度很快。
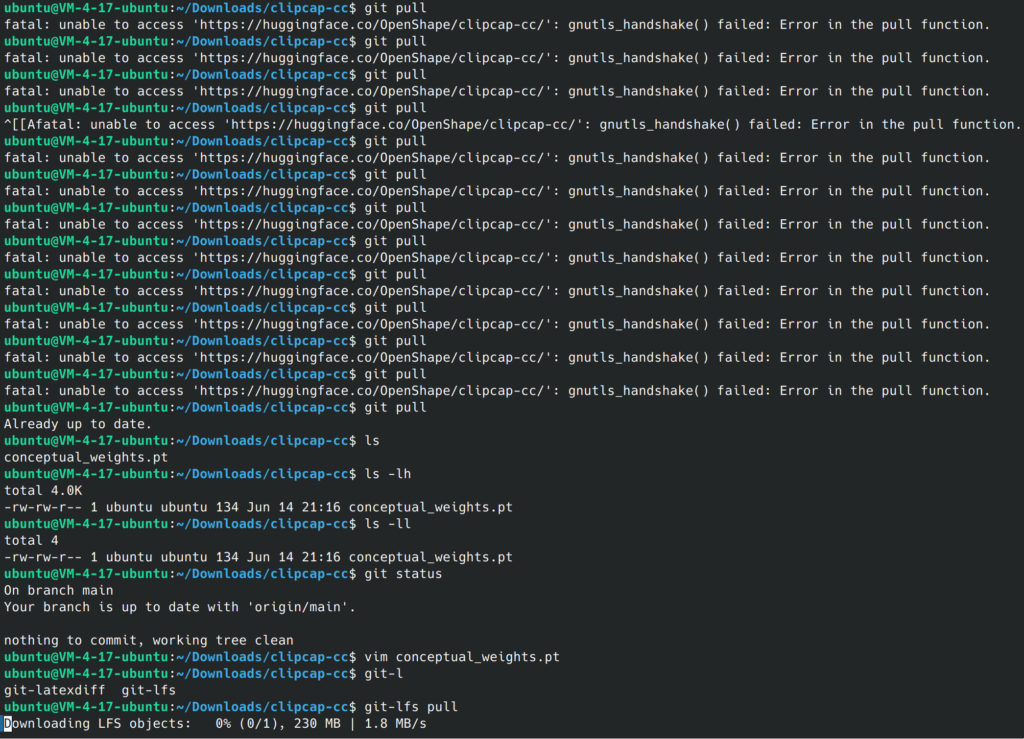
huggingface反爬很强,我们需要多次git pull
下载完后,将文件传给部署项目的服务器,记得指定权重路径参数。
数据预处理
这步对于所有项目的部署可能不是必要的,但我们这篇论文由于模型原因,需要提前处理图片数据,计算每个图片的embedding和相应的一组最不相似的负样本。这一步的代码在scripts/compute_hard_negatives.py中,运行前需要指定数据集路径参数,查看所有参数的方法同上。运行后将output的两个文件移到合适的位置,供train.py脚本使用。
要找到这个脚本文件其实也是一件有技术难度的活
如何快速了解一个程序文件的功能作用?(#tip5):
最佳推荐:ChatGPT
实际上,chatgpt还有很多妙用(#tip6):
- 上文运行python程序需要很多参数,但是我们不知道这些参数的作用,这时我们可以把help的内容提供给chatgpt,然后说明我们的需求,就可以看到chatgpt生成的完整的运行命令了。
- 程序报错,我们不知道是什么原因,这时我们可以把报错信息提供给chatgpt,然后说明我们的需求,就可以看到chatgpt生成的解决方案了。
- 提供多篇论文的bibtex,指定IEEE-TPAMI格式,chatgpt可以生成一个完整的参考文献列表,写周报常用。
你的ChatGPT何必是ChatGPT
很不幸的是,运行该文件时又报错了,这次是NoModuleError,提示找不到dataloads库。检查代码发现,这个库是作者自己写的,包含在项目里,但是我们已经安装过了,而且vscode代码检查也没报错。这是为何?
这是因为我们在命令行运行compute_hard_negatives.py时,python解释器没有在当前目录下寻找库文件。因此我们需要指定“PYTHONPATH=.”的环境变量,这样python解释器才能找到我们的库文件。
网上的解决方法都是指定vscode配置文件launch.json,在里面添加环境变量,依个人喜好选择
总结
目前我就做了这么多,还有很多东西没做完,例如训练模型、测试模型、调参和使用tensorboard等等。
这篇论文的部署过程其实很麻烦,但是我觉得还是值得的。整个部署过程能够积累很多经验,这些经验我都在原文处添加了“#tip”字样,方便大家搜索。
本篇文档有些地方简化了描述,还有很多不完善的地方。希望我的文档能提供帮助,也希望能有更多人学会如何部署项目。
written by Cheanus