0. ResNet
我们首先以ResNet为本文起点:
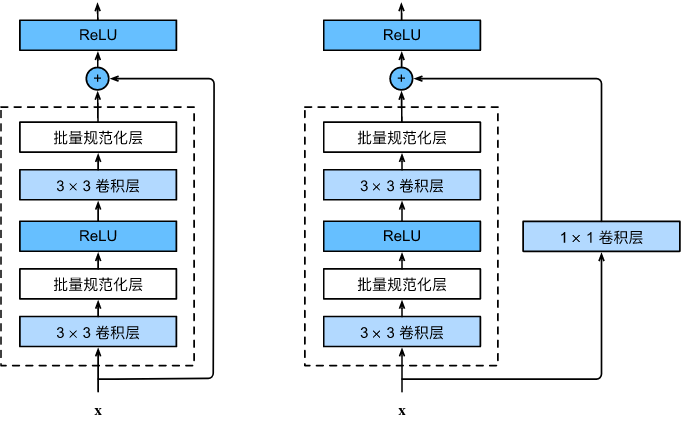
ResNet主要的创新之处在于添加了skip connection, 这样的好处有:
- 在反向传播中,skip connection直接传递了梯度变化,避免了深层网络的梯度消失,使网络对target变化更加敏感。
- ResNet包含大量的恒等映射block, 实现了自适应深度的能力。这有点像机器学习中的Boosting思想——当浅层网络不足以学习、留给深层网络的残差梯度变化较大时,后者就会被激活,加入到训练中,反之则不然。
ResNet原论文还有一些常规改进,例如调整某些卷积核顺序、替换为池化层等。
论文链接:https://arxiv.org/abs/1512.0338
1. 调整、添加和替换
ResNet的常规改进包括调整某些层的顺序、添加池化层等方法。
1.1 ResNetV2
ResNetV2 = ResNet + 调整ReLU、BN位置
生活中我们遇到的残差都是有正有负的。然而,观察上面的ResNet basic block不难发现,由于ReLU的存在,残差块只能输出非负数,这显然制约了ResNet的表达能力。
作为一个残差块,有正有负才是常态,这正是ResNetV2所要解决的问题。
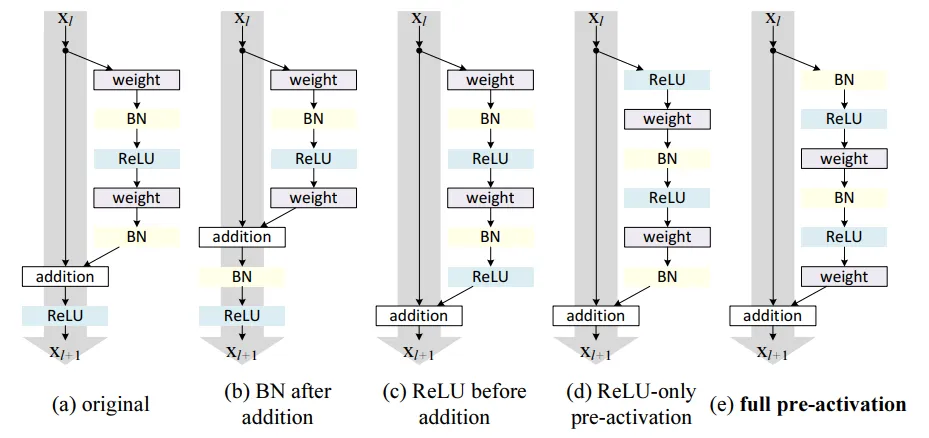
上图中,(a)是ResNet, 之后的是论文给出的测试网络结构。(b)(c)的效果都比baseline要差,(d)(e)将ReLU调整到残差块一个分支内部,避免了非负的输出。
(e)相比其他网络的一个好处是:所有weight都是BN后立即被输入ReLU, 而非BN后又混杂了其他信息(例如(a)就又加上了x的数据),这确保了BN发挥最大性能。实验中发现它能很好地避免过拟合。
1.2 Wide ResNet
ResNeXt = ResNet + channels倍增
实验表明,ResNet和ResNetV2都可以通过增大网络深度来提高网络性能,而WideResNet尝试增加网络宽度。
WideResNet所增加的宽度实际上指的是卷积层的channels数量,如果channels不增加,那么它实际上就是ResNet.
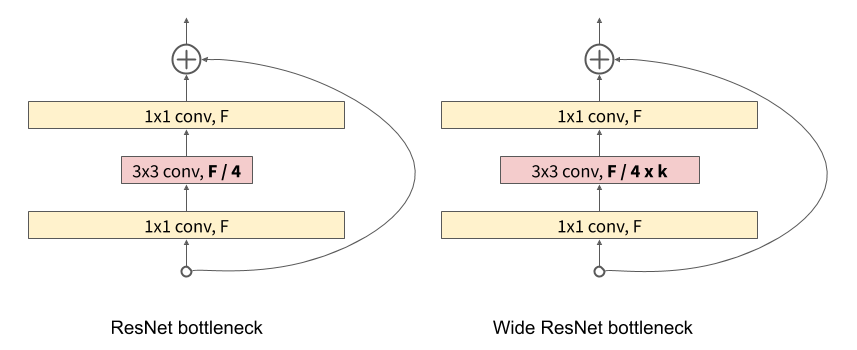
左图是ResNet论文提出的一个结构,通常用于ResNet50及以上参数的网络,相比之前的basic block参数量大幅下降。右图是WideResNet, 可以看到卷积核宽度变多了。
实验效果:增加宽度能提升网络性能,并且增加宽度比增加深度更有计算效率(尽管参数量更多,但是硬件加速效果更好)。
2. 分组/分支卷积
分组卷积(group convolution)指将输入特征图按通道均分为 g 组,然后对每一组进行常规卷积,最后再把所有组的输出concat。
多分支卷积(Multi-branch convolutional networks)就是使用不同大小的卷积核分别卷积,之后融合(fuse)。
2.1 ResNeXt
ResNeXt = ResNext + split-transform-merge/group convolution
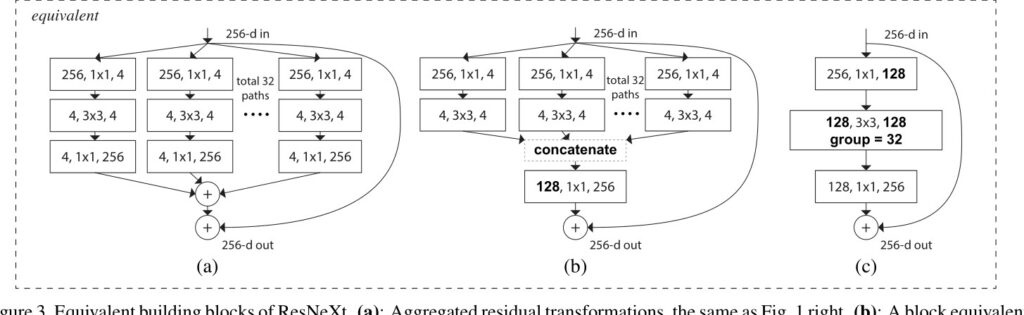
上面三幅图是等价的,都是ResNeXt的网络结构,(c)通过分组卷积简化了形式,但运算逻辑没有改变。
从(a)(b)可以看出,网络借鉴了inception块的split-transform-merge思想,不过每个分支的结构都是相同的。
基于以上结构特点,作者提出了一个区别于网络宽度和深度的新维度:基数(Cardinality),它是指transform的个数。论文中说,这是比深度和宽度更有效的一个维度。
ResNeXt在参数相同的情况下,实现了比ResNet更优的性能。
论文链接:https://arxiv.org/abs/1611.05431
2.2 SKNet
SKNet = ResNet + selective kernel ( = split + fuse + select)
SKNet添加了select步骤,实现了自适应调整感受野尺寸,可以捕获具有不同尺度的目标物体。
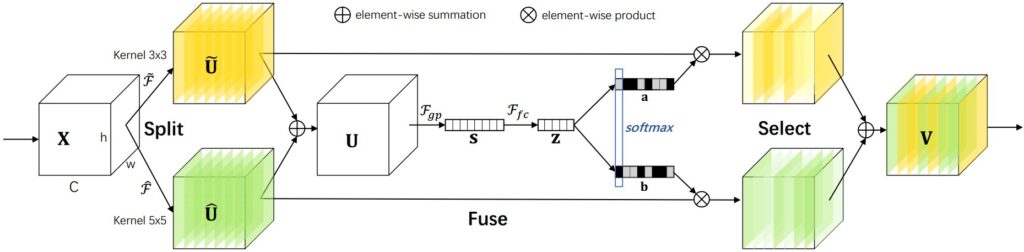
上图可用3个步骤来概括:
- split: 使用两种不同大小的卷积核3×3 $\widetilde{F}$和5×5 $\hat{F}$,分别对X分组卷积(省略BN、ReLU等细节)
- fuse: 把分支卷积后的$\widetilde{U}$和$\hat{U}$元素加和,经过$F_{gp}$(全局平均池化)、$F_{fc}$(全连接)和softmax后,得到channel上的注意力矩阵a、b
- select: 将得到的a、b分别元素乘上$\widetilde{U}$和$\hat{U}$,得到选择后的feature, 最后加和得到最终输出
论文链接:https://arxiv.org/abs/1903.06586
3. 注意力
3.1 SE-ResNet
SE-ResNet = ResNet + 通道注意力
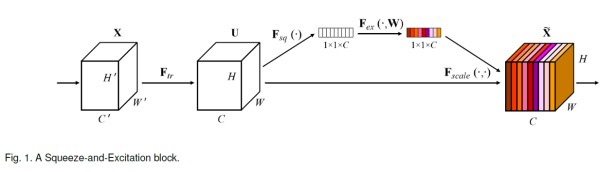
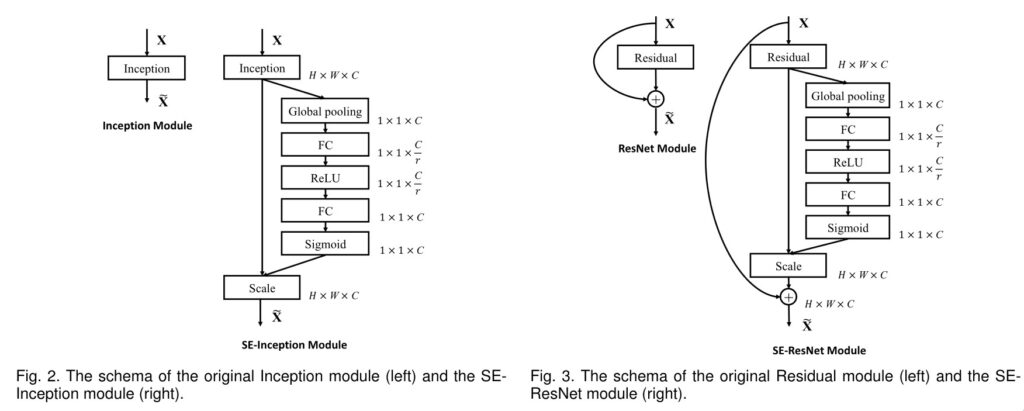
如图所示,仅在通道上使用了注意力机制,就实现了模型的改造。详细的说,SE分为两个步骤:
- squeese: 对应global pooling层
- exitation: 对应FC、ReLU、FC、sigmoid层,第一个FC先降维,第二个FC再升维
论文链接:https://arxiv.org/abs/1709.01507
3.2 ResNeSt
论文链接:https://arxiv.org/abs/2004.08955v2
4. 结构重参数化
结构重参数化(structural re-parameterization)指的是首先构造一系列结构(一般用于训练),并将其参数等价转换为另一组参数(一般用于推理),从而将这一系列结构等价转换为另一系列结构。
4.1 RepVGG
RepVGG = ResNet + 多分支训练 + 单路推理
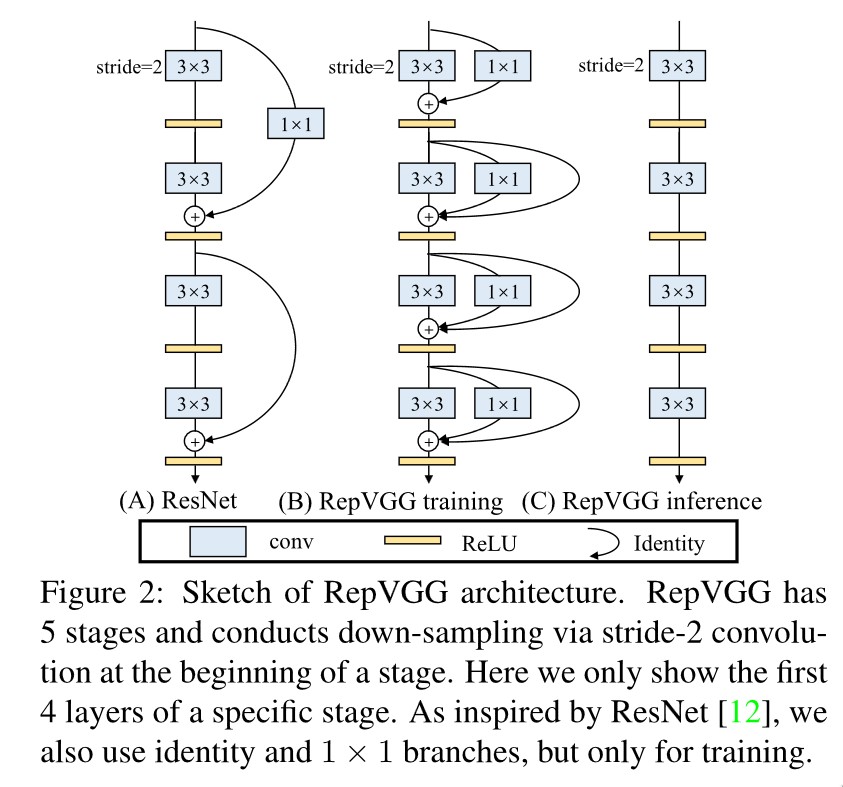
RepVGG的结构和思想十分简洁,但却在速度和精度上双双取得了不错的成绩:
- 卷积核最大3×3, 计算时间非常快
- 推理时将多路分支合并为一路,加快推理速度
该作者还有一篇用结构重参数化来实现网络参数压缩的论文ResRep (知乎作者讲解),idea也十分巧妙,最后的结果SOTA。
参考链接
[1] 残差网络的进化-从ResNet到ResNeSt
[2] 【论文泛读】 ResNeXt:深度神经网络的聚合残差变换(ResNet的改进,提出了一种新的维度)-阿里云开发者社区
[3] 【论文解读】SKNet网络(自适应调整感受野尺寸)
[4] ResNet最强改进版来了!ResNeSt:Split-Attention Networks – 知乎