这篇写于6月份放假前,现在已经有很多新的变化,我已在原文旁加以注释
最近无聊,距离离校日期还早,趁618打折我入手了国内的tx云服务器,这时候就在想着能不能用它来干点有用的事。
正好,某高校要求学生每天都要在网上填写相关健康信息,进行“每日疫情填报”。上次寒假时我因为漏打卡一天,不得不填写额外的打卡表。为了今年能够安安心心地过个暑假,我于是准备写个打卡脚本,放在云端自动运行。
由于个人隐私原因,本文仅提供有限的截图和代码,可能不会对你提供太多的帮助
本人大一非cs专业,爬虫入门不到1年,水平有限,文章可能存在不少的错误,希望读者原谅
1. 网站抓包分析
我原以为这个填报功能就是个简单的post请求,后面才发现有点复杂
首先,在填报完健康信息、点击提交那一刻,浏览器的确发送了一个post请求,data里携带了我的所有健康信息,响应中写道:“state”: “1”。根据上下文判断,这个就是填报成功的状态码。因此我们的主要任务就是利用脚本模拟本次请求(我们把该请求称作请求A)。
随后查看该请求的url,发现其中有串无规律的字符串和unix时间戳,对该字符串使用开发者工具的查找功能,定位到其以文本形式存在于网页打开时的请求B所得到的一个响应内。
简单写个脚本可以判断,请求A和请求B都必须携带一个特殊的动态会话cookie才能返回正确的内容,检查后发现该cookie(假设称作cookie1)并非来自于账户主页,那么它是从哪来的呢?
在开发者工具中删除该cookie1,重新进入“健康填报”网页,抓包出现了4次302重定向,在第1个响应中便出现了’set-cookie’,经对照后判断它就是我们正在寻找的cookie1。
已经结束了吗?未必
我之后才发现这个cookie直接拿来用是无效的,之后我继续研究那4次重定向,发现网页调用了学校的“统一身份认证”界面的API,在该页面进行了自动验证后,又携带了3个新的cookie2跳转回“健康填报”页面,经过这4次重定向后cookie1才生效。
因此目前的工作在于如何得到cookie2,也就是研究“统一身份认证”平台的登录机制。
犹记得我去年暑假刚学爬虫时就研究过这个登录界面,然而由于当时自己实力不足,只能不了了之
首先仍然是聚焦于最关键的登录按钮,模拟登录时,抓包出现了一个post请求,其中自然有我的账户名和密码,还有3个奇怪的cookie,其中一个可以追溯到进入登录界面时的一个响应里,另外两个cookie值为时间戳,它俩的名称又可追溯至另外的一个响应中……
2022.7.20更新:月初“统一身份认证”平台进行了小幅更新,登录时的post请求中多了一个”execution”字段,不出所料,它就藏在登录网页源代码里面。
以上过程着实繁琐,以顺序流程图来简化表示,整个流程如下:
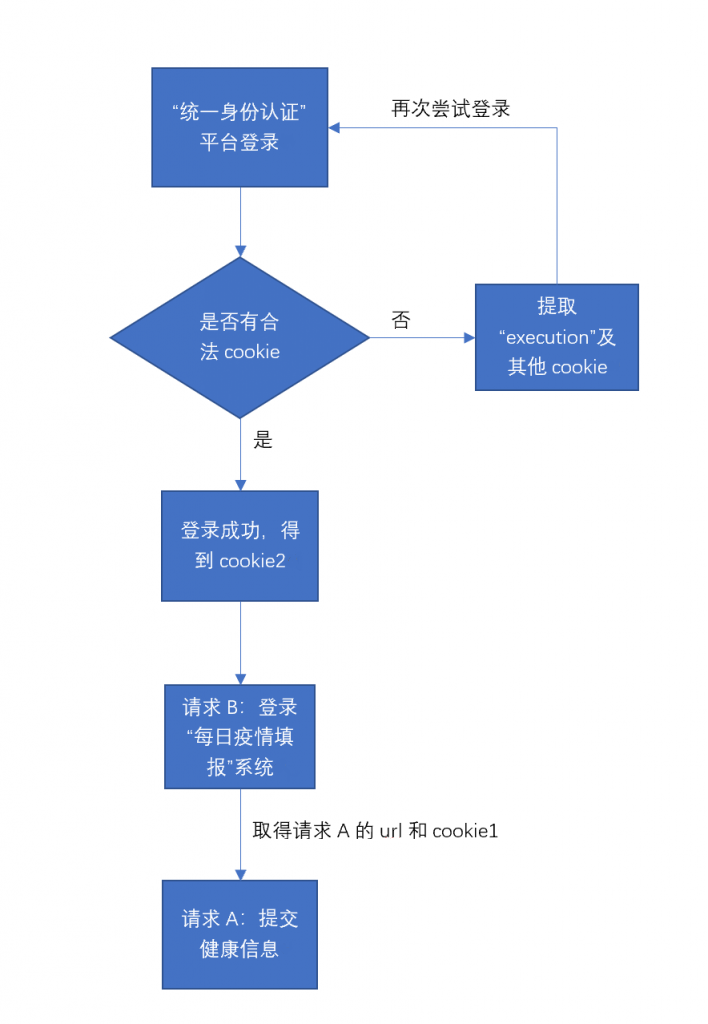
至此,整个“健康填报”的前端机制已经探明,剩下的就交给脚本吧!
2. 邮件提醒
如果哪天因为莫名其妙的原因,比如网络不畅、cookie失效,脚本运行出现问题怎么办?我很自然地想到可以使用发邮件的方式及时提醒我。
python里我使用的是内置smtplib库,利用了qq邮箱的smtp服务,同时从某位大佬那学来了邮件发送代码,最终得以实现邮件提醒问题信息的功能。详细信息可以搜索这个库及相关教程。
3. 云服务器
至于云服务器,我踩的坑实在是太多了!最初我安装的是Windows服务器,搭建好python爬虫环境后,运行却报”default backend 404″,我还以为是自己的原因,之后下定决心换了Linux(Ubuntu)系统,下载了python3.9.13,安装了必要的requests库(就这3句话,我开始从0学Linux,中途踩坑数十次)。
为了方便快捷,我使用本地PuTTY登录和操作服务器,通过WinSCP传输文件。
结果脚本运行后还是404,但是本地运行起来好好的啊?
经过一番探索,我终于发现,是学校网站封了我的云服务器ip,导致一直无法建立链接,从而404报错。
没办法,我只好下“血本”买来代理ip(不用免费ip主要是担心隐私泄露问题),经过尝试后,服务器终于显示“state”: “1”,网页端的健康打卡记录也随之更新了。
2022.7.20更新:实际上隔了几天我的云服务器就可以正常访问学校网络了,因此不再使用代理ip。至于钱嘛,打水漂咯~~~
4. 自动定时
在云服务器ip被封后,我甚至还使用了Windows系统的定时任务计划功能,打算以本地电脑自动运行脚本来替代,当然这一点也不高大上。不论是代理ip期间,还是在ip解封后,我都是使用云服务器的contab定时命令自动运行脚本:
0 8 * * * /home/lighthouse/Python/auto_fill_linux.py
上面的命令指每天8点运行脚本
多次测试结果表明,该自动填报系统能够正常运行
5. 代码
requests库中的session能自动记录cookie,并在下次请求中携带,对我来说极为方便,因此代码里大量使用了session
2022.7.20更新:放假回家后健康信息有所变动
以下涉及隐私信息的内容以*代替
import re
import time
import requests
import smtplib
import json
from email.mime.text import MIMEText
from requests import utils
def email(content):
# 设置服务器所需信息
# qq邮箱服务器地址
mail_host = 'smtp.qq.com'
# qq用户名
mail_user = 'qq账号'
# 密码(部分邮箱为授权码)
mail_pass = '授权码'
# 邮件发送方邮箱地址
sender = 'qq邮箱'
# 邮件接受方邮箱地址,注意需要[]包裹,这意味着你可以写多个邮件地址群发
receivers = ['qq邮箱']
# 设置email信息
# 邮件内容设置
message = MIMEText(content, 'plain', 'utf-8')
# 邮件主题'
message['Subject'] = '每日疫情自动填报报告'
# 发送方信息
message['From'] = sender
# 接受方信息
message['To'] = receivers[0]
# 登录并发送邮件
smtpObj = smtplib.SMTP()
# 连接到服务器
smtpObj.connect(mail_host, 25)
# 登录到服务器
smtpObj.login(mail_user, mail_pass)
# 发送
smtpObj.sendmail(sender, receivers, message.as_string())
# 退出
smtpObj.quit()
url = "https://***"
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 'cache-control': 'max-age=0',
'referer': '***',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
session = requests.session()
try:
response = session.get(url, headers=headers)
except requests.exceptions.ConnectionError as e:
email('网络错误,每日疫情自动填报系统无法正常运行,请及时手动填报')
exit()
response.encoding = 'utf-8'
str1 = re.search('var hmSiteId = "(.*?)"', response.text)
requests.utils.add_dict_to_cookiejar(session.cookies, {("Hm_lvt_" + str1.group(1)): str(int(time.time()))})
requests.utils.add_dict_to_cookiejar(session.cookies, {("Hm_lpvt_" + str1.group(1)): str(int(time.time()))})
execution = re.search('name="execution" value="(.*?)"', response.text)
data = {
'username': '***',
'password': '***',
'currentMenu': '1',
'execution': execution.group(1),
'_eventId': 'submit',
'geolocation': '',
'submit': 'One moment please...'
}
session.post(url, data=data, headers=headers) # received login coolie
url = '***'
session.get(url, headers=headers)
cookie = 'JSESSIONID=' + session.cookies.get_dict()['JSESSIONID']
url = '***'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Referer': '***',
'Host': '***',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'Cookie': cookie
}
headers2 = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Content-Length': '196',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': '***',
'Origin': '***',
'Referer': '***',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'cookie': cookie
}
# data = {
# 'hsjc': '1',
# 'xasymt': '1',
# 'actionType': 'addRbxx',
# 'userLoginId': '***',
# 'szcsbm': '1',
# 'bdzt': '1',
# 'szcsmc': '在学校',
# 'sfyzz': '0',
# 'sfqz': '0',
# 'tbly': 'sso',
# 'qtqksm': '',
# 'ycqksm': '',
# 'userType': '2',
# 'userName': '***',
# } # 在学校的情况
data = {
'hsjc': '1',
'sfczbcqca': '',
'czbcqcasjd': '',
'sfczbcfhyy': '',
'czbcfhyysjd': '',
'actionType': 'addRbxx',
'userLoginId': '***',
'userName': '***',
'szcsbm': '***',
'szcsmc': '***',
'sfjt': '0',
'sfjtsm': '',
'sfjcry': '0',
'sfjcrysm': '',
'sfjcqz': '0',
'sfyzz': '0',
'sfqz': '0',
'ycqksm': '',
'glqk': '0',
'glksrq': '',
'gljsrq': '',
'tbly': 'sso',
'glyy': '',
'qtqksm': '',
'sfjcqzsm': '',
'sfjkqk': '0',
'jkqksm': '',
'sfmtbg': '',
'userType': '2',
'qrlxzt': '3',
'bdzt': '1',
'xymc': '***',
'xssjhm': '***',
} # 在我家的情况
response = session.get(url, headers=headers)
response.encoding = 'utf-8'
match = re.search(r"url:'(.*?)'", response.text)
if match is None:
email("cookie失效")
else:
url2 = r"***" + match.group(1)
response = requests.post(url2, data=data, headers=headers2)
response.encoding = 'utf-8'
if response.text[-3] != '1':
email("自动填报失败")
print(response.text)
实际上,headers里的许多信息是不必要的,但我为了图方便选择全部复制。顺便我还学会了怎么在pycharm中用正则表达式为headers批量添加双引号
后记
参杂着考试周复习,整个过程花了差不多3天
暑假再想想如何利用云服务器做更多有趣的事吧