写在前面
自618买云服务器到现在,仅一个多月。但在这点时间里,我码出了”每日疫情填报“系统,用命令行便完成了WordPress网站搭建。另外,ICP+公安备案+SSL证书也十分顺利地审批下来了 。一个月前的我,大概根本想不到自己会用云服务器玩出这么多的花样吧。
本文提到的”成绩实时监控系统“也算是杰作之一。我在完成了”每日疫情填报“系统之后,就马不停蹄地花了1天时间实现了它。一个月以来,该系统运行极佳,于是我打算今后长期使用它。
由于近期时间较多,本文我会花时间提到尽可能多的技术细节。
WHAT
什么?成绩也能实时监控?做得怎么样?怎么做到的?别急,我慢慢说来。
如名所示,“成绩实时监控系统”能够以较高频率(我设置的20min每次)扫描我在教务处的成绩单,一有更新就通过邮件通知到我的邮箱,于是我的手机或是其他设备就能及时接收到新鲜出炉的成绩详情,这份邮件包括了我新出的成绩及学科、学分、绩点,并在段落最后附有我的最新GPA。
如此,再也不用忍受焦急地打开教务系统盯成绩的紧张感了!
HOW
我们一步一步地来实现这个系统吧,首先做的是最基础的抓包分析。
1. 抓包分析
东大男子职业技术学院的教务系统在今年3月份全面改版,界面变美观的同时,也留下了许多“有趣”的API,我之后可能会详细地写出来。今天我们着重分析成绩信息界面。
打开F12开发者工具-网络,刷新成绩信息界面,如下所示
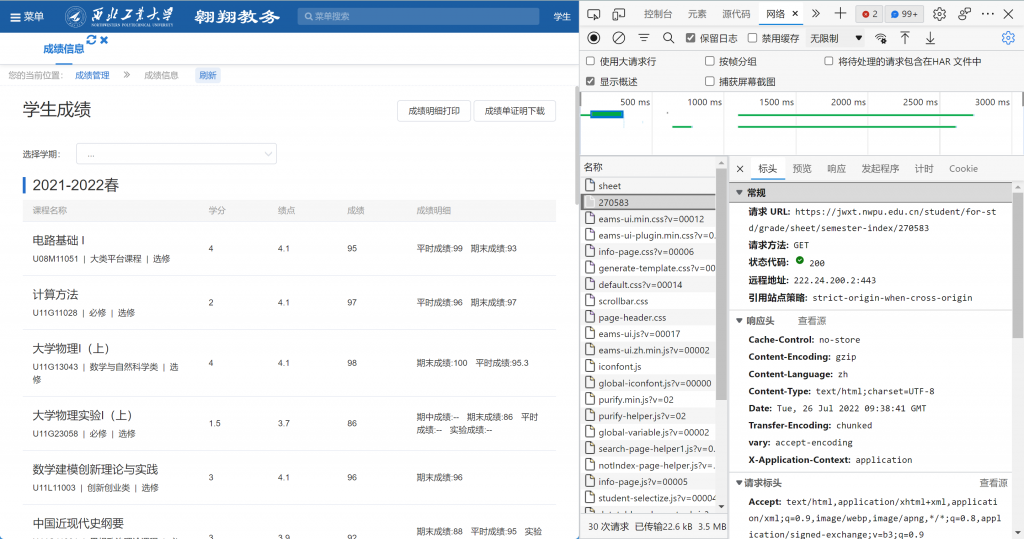
接下来就要找包含成绩信息的请求包了。点击任意一个请求名称,按Ctrl+F查找“电路基础”,我们定位到了网络最后的一个请求中,打开预览,我们的确发现了所有的成绩信息,那么这就是我们接下来要实现的请求了。
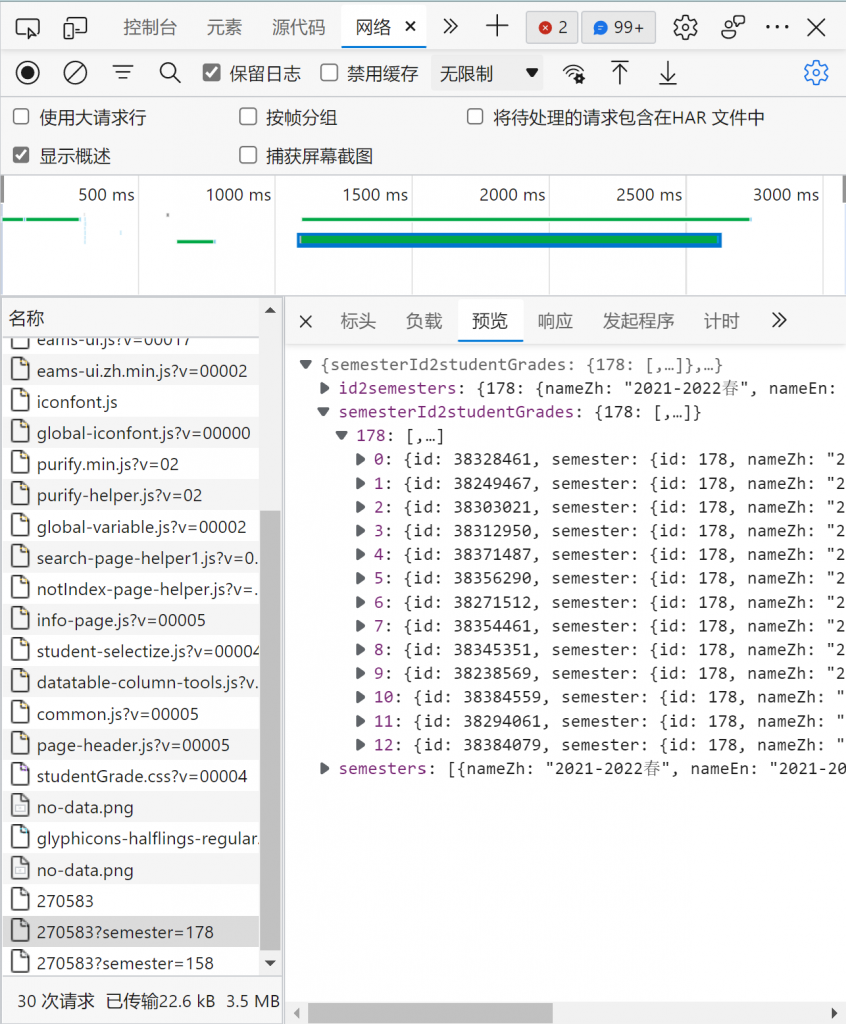
请求响应的是一个json格式的信息。我们还可以发现,图中共有两个相似的请求,不同在于其“semester”值不同,简单查看可以知道这是两个学期的成绩信息,分成了两个url依次进行请求。
哪里去找这个“semester”呢?经过仔细查找,我发现它就藏在框架源代码里:
<div class="row" style="margin: 20px 0px 10px;">
<label class="col-sm-2 semester" for="semester">选择学期:</label>
<div class="col-sm-5">
<select class="selectize" id="semester" name="semester">
<option value="">...</option>
<option value="178">2021-2022春</option>
<option value="158">2021-2022秋</option>
</select>
</div>
</div>
这个框架源代码来自于我们所抓取到的第一个请求中,在得到框架源代码后,我们既可以使用lxml定位到上述option的value属性,也可以像我的代码一样直接正则匹配获得。
经过以上分析,现在我们已经可以爬取到成绩列表信息了。另外一个问题是cookie,我已经在随笔:利用云服务器+脚本实现自动“健康填报”中实现了模拟登录获取cookie并存储在session里,本文不再赘述。
经过多次权衡取舍,我最终选择了如图所示的成绩信息txt存储规范,即“科目,成绩,绩点,学分”,一个科目占一行,这样读写都方便。

下面是部分代码:
url = 'https://jwxt.nwpu.edu.cn/student/sso-login'
session.get(url, headers=headers) # 登录教务系统
response = session.get('https://jwxt.nwpu.edu.cn/student/for-std/grade/sheet/semester-index/270583', headers=headers)
semester = re.findall('<option value="(.+?)"', response.text) # 获得semester列表
headers2 = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Host': 'jwxt.nwpu.edu.cn',
'Referer': 'https://jwxt.nwpu.edu.cn/student/for-std/grade/sheet/semester-index/270583',
'sec-ch-ua': '"".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103""',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"', # 当时我是在云服务器linux系统用Chrome抓包,以便贴合其环境
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'X-Requested-With': 'XMLHttpRequest' # 这个很关键,使响应以json格式返回
}
grades = []
for sem in semester:
url = 'https://jwxt.nwpu.edu.cn/student/for-std/grade/sheet/info/270583?semester=' + sem #每次访问一个学期的成绩单
response = session.get(url, headers=headers2)
response = json.loads(response.text)['semesterId2studentGrades'][sem]
for course in response:
name = course['course']['nameZh']
gaGrade = course['gaGrade']
gp = str(course['gp'])
credit = course['course']['credits']
grades.append(f'{name}, {gaGrade}, {gp}, {credit}') # 用列表依次存储各学科、成绩、绩点和学分信息
2. 成绩信息文件处理
我们并不想要所有成绩信息,我们只需要最新的成绩即可。唯一的实现方法便是本地存储所爬取的成绩信息,每次爬取后将所得成绩与本地信息相对比,找出是否有变化的成绩信息,我们用Python的集合函数来实现这一操作。
另外,由于新成绩会影响原有GPA,而我们更关心后者,因此我还从“学生画像”中通过抓包找到了GPA的API,把它附到了邮件正文末。
对于新成绩,我最关心的其实是科目名、成绩和绩点,对学分的关注要弱一点,因此我把新成绩的科目名、成绩和绩点直接放到了邮件标题上,方便我及时看见。
另一个问题是,无论标题还是正文,我们都应该考虑到可能存在出多门新成绩的可能;此外,当本地成绩文件不存在时,我们应当自动创建它。这些考虑能够提高代码的健壮性。
os处理代码如下:
f_path = 'Documents/grades.txt' # 本地成绩信息存储路径(我用的Ubuntu,对,就是你现在访问的网站服务器系统)
if os.path.isfile(f_path):
fo = open(f_path, "r+")
grades2 = fo.read().split('\n')
new_grades = set(grades).symmetric_difference(set(grades2)) # 集合相减
if len(new_grades) != 0:
response = session.get('https://jwxt.nwpu.edu.cn/student/for-std/student-portrait/getMyGpa?studentAssoc=270583', headers=headers)
gpa = str(json.loads(response.text)['stdGpaRankDto']['gpa']) # 获取GPA
title = [','.join(x.split(', ')[0:3]) for x in new_grades]
title = ';'.join(title) # 标题中用分号隔开不同成绩信息
content = "科目 成绩 绩点 学分\n" + \
"\n".join(new_grades) + \
f"\n成绩已更新,概要如上\n新的绩点诞生了:{gpa}\n继续加油~~~"
email(title, content) # email是我封装的邮件发送函数,详见文末完整代码
fo.close()
fo = open(f_path, "w")
fo.write('\n'.join(grades))
else:
fo = open(f_path, "w")
fo.write('\n'.join(grades))
fo.close()
4. 定时运行
我们仍然使用老朋友crontab来帮助我们定时运行脚本,设置每天7点后间隔20分钟运行一次脚本:
*/20 7-23 * * * python3 /home/ubuntu/mypython/GradesMonitorLinux.py
程序效果
以下是我的部分邮件列表(我是用自己的邮箱给自己自发邮件):
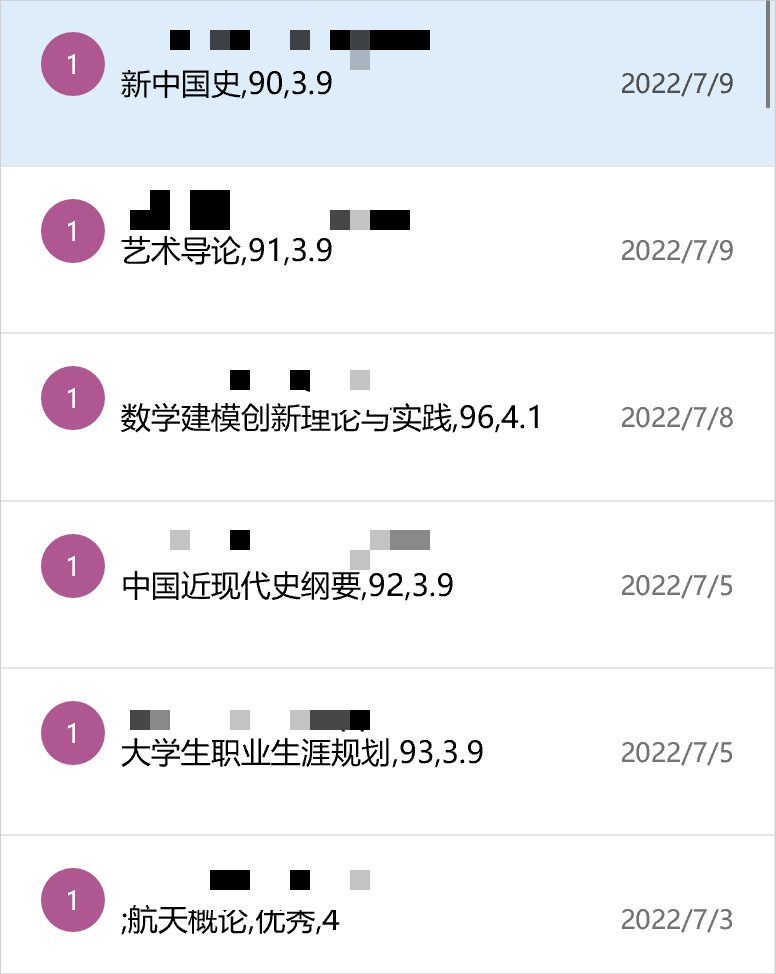
实测评估,“成绩实时监控系统”真正做到了“实时”二字,每次我了解成绩都快人一步,效果好于预期。
在这之后,我又用WordPress建立了这个网站,其中也不乏可道之处,有空时再来说说吧。
彩蛋
几天前从b站上我了解到了GPA排名的API,可惜现在那个视频被删了(估计是隐私泄露了?本文也如此,有技术者自然能推断我的身份),现分享如下。
打开教务系统-学生画像,打开F12开发者工具,刷新界面,在网络中找到“getMyGrades…”的请求,响应是json格式,其中既有gpa,也有相应排名,属性路径为stdGpaRankDto.rank
如果在界面中选择特定学期,还可以抓包到相应学期的gpa及排名,这里不便赘述。
至于你问我为什么不把排名写进邮件正文里,我懒感觉没必要。
附:完整代码
import json
import os.path
import re
import time
import requests
import smtplib
from requests import utils
from email.mime.text import MIMEText
def email(title, content):
# 设置服务器所需信息
# qq邮箱服务器地址
mail_host = 'smtp.qq.com'
# qq用户名
mail_user = '***'
# 密码(部分邮箱为授权码)
mail_pass = '***'
# 邮件发送方邮箱地址
sender = '***'
# 邮件接受方邮箱地址,注意需要[]包裹,这意味着你可以写多个邮件地址群发
receivers = ['***']
# 设置email信息
# 邮件内容设置
message = MIMEText(content, 'plain', 'utf-8')
# 邮件主题'
message['Subject'] = title
# 发送方信息
message['From'] = sender
# 接受方信息
message['To'] = receivers[0]
# 登录并发送邮件
smtpObj = smtplib.SMTP()
# 连接到服务器
smtpObj.connect(mail_host, 25)
# 登录到服务器
smtpObj.login(mail_user, mail_pass)
# 发送
smtpObj.sendmail(sender, receivers, message.as_string())
# 退出
smtpObj.quit()
url = "https://uis.nwpu.edu.cn/cas/login?service=https%3A%2F%2Fecampus.nwpu.edu.cn%2F%3Fpath%3Dhttps%3A%2F%2Fecampus.nwpu.edu.cn"
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 'cache-control': 'max-age=0',
'referer': 'https://ecampus.nwpu.edu.cn/main.html',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
session = requests.session()
try:
response = session.get(url, headers=headers)
except requests.exceptions.ConnectionError as e:
email('成绩实时监控系统:网络错误')
exit()
response.encoding = 'utf-8'
str1 = re.search('var hmSiteId = "(.*?)"', response.text)
requests.utils.add_dict_to_cookiejar(session.cookies, {("Hm_lvt_" + str1.group(1)): str(int(time.time()))})
requests.utils.add_dict_to_cookiejar(session.cookies, {("Hm_lpvt_" + str1.group(1)): str(int(time.time()))})
execution = re.search('name="execution" value="(.*?)"', response.text)
data = {
'username': '***',
'password': '***',
'currentMenu': '1',
'execution': execution.group(1),
'_eventId': 'submit',
'geolocation': '',
'submit': 'One moment please...'
}
session.post(url, data=data, headers=headers) # received login coolie
url = 'https://jwxt.nwpu.edu.cn/student/sso-login'
session.get(url, headers=headers)
response = session.get('https://jwxt.nwpu.edu.cn/student/for-std/grade/sheet/semester-index/270583', headers=headers)
semester = re.findall('<option value="(.+?)"', response.text)
headers2 = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Host': 'jwxt.nwpu.edu.cn',
'Referer': 'https://jwxt.nwpu.edu.cn/student/for-std/grade/sheet/semester-index/270583',
'sec-ch-ua': '"".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103""',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'X-Requested-With': 'XMLHttpRequest'
}
grades = []
for sem in semester:
url = 'https://jwxt.nwpu.edu.cn/student/for-std/grade/sheet/info/270583?semester=' + sem
response = session.get(url, headers=headers2)
response = json.loads(response.text)['semesterId2studentGrades'][sem]
for course in response:
name = course['course']['nameZh']
gaGrade = course['gaGrade']
gp = str(course['gp'])
credit = course['course']['credits']
grades.append(f'{name}, {gaGrade}, {gp}, {credit}')
f_path = 'Documents/grades.txt'
if os.path.isfile(f_path):
fo = open(f_path, "r+")
grades2 = fo.read().split('\n')
new_grades = set(grades).symmetric_difference(set(grades2))
if len(new_grades) != 0:
response = session.get('https://jwxt.nwpu.edu.cn/student/for-std/student-portrait/getMyGpa?studentAssoc=270583', headers=headers)
gpa = str(json.loads(response.text)['stdGpaRankDto']['gpa'])
title = [','.join(x.split(', ')[0:3]) for x in new_grades]
title = ';'.join(title)
content = "科目 成绩 绩点 学分\n" + \
"\n".join(new_grades) + \
f"\n成绩已更新,概要如上\n新的绩点诞生了:{gpa}\n继续加油~~~"
email(title, content)
fo.close()
fo = open(f_path, "w")
fo.write('\n'.join(grades))
else:
fo = open(f_path, "w")
fo.write('\n'.join(grades))
fo.close()